


Snapdragon X Series: Todo sobre la Arquitectura con la que Qualcomm quiere dominar el mercado de portátiles con IA
por Antonio DelgadoLas nuevas generaciones de CPU Oryon, GPU Adreno X1 y NPU Hexagon se estrenan en los Snapdragon X
El Snapdragon X Elite, y su hermano pequeño, el Snapdragon X Plus, son los nuevos procesadores de Qualcomm orientados en exclusiva al mercado del PC. Están basados en su propia arquitectura Oryon en la parte de CPU y cuentan con GPus de nueva generación y una NPU con la que prometen dar un salto generacional considerable en cuanto a la aceleración de tareas de Inteligencia Artificial se refiere.
Ya conocíamos gran parte de sus especificaciones y también hemos podido probar de lo que son capaces en IA en este último Computex 2024, pero ahora llega el turno de hablar en detalle de su arquitectura. Tanto la parte de CPU, con Oryon, como la GPU Adreno X1 y también la NPU Hexagon, introducen nuevos diseños y características con las que Qualcomm quiere hacerse un hueco a lo grande en el mercado de portátiles (y también de otros formatos de PC).
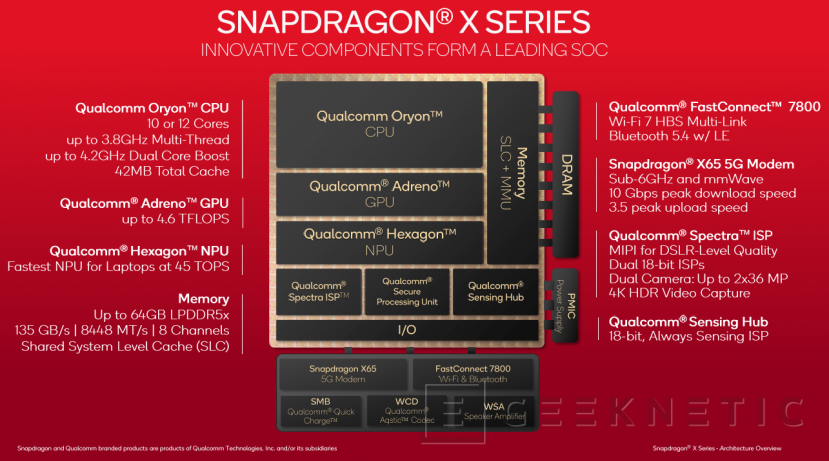
Todo ello integrado en estos SoC junto a lo último en memoria LPDDR5x, módem Qualcomm FastConnect 7800 con WiFi 7 y Bluetooth 5.4 o la conectividad 5G que ofrece el módem Snapodragon X65 disponible en algunos modelos que llegarán al mercado.
Tampoco nos podemos olvidar de tecnologías que ya conocemos de sus SoCs anteriores, tanto de portátiles como de smartphones, como el ISP Spectra para la gestión de las cámaras o el Sensing HUB encargado del control de los sensores en segundo plano y con bajo consumo.
Comencemos este repaso a las novedades más importantes de la arquitectura de los Snapdragon X Elite y Snapdragon X Plus.
La arquitectura de CPU Oryon llega al mercado
Aunque la mayoría de atención de estos Snapdragon X Elite se está poniendo en sus capacidades de IA y sus NPU, lo cierto es que suponen el debut de la arquitectura Oryon que surge tras la adquisición de Nuvia. Estos diseños dicen adiós a los núcleos personalizados basados en los diseños Cortex de ARM, aunque mantienen las instrucciones ARMv8.7 y, por tanto, esa arquitectura base.
Sabemos que habrá distintas variantes con 10 y 12 núcleos dependiendo de si hablamos del Snapdragon X Plus o del Snapdragon X Elite, además de distintas configuraciones de velocidad. Los más potentes alcanzarán 3,8 GHz de velocidad en todos los núcleos, y hasta 4,2 GHz en Boost de dos núcleos. La caché total será de 42 MB e irán acompañados de hasta 64 GB de memoria LPDDR5x a 8.448 MT/s y con 135 GB/s de ancho de banda.

Cada procesador contará con hasta tres clústeres dotados de su propia caché L2, una interfaz BIU para la interconexión (Bus Interface Unit) y cuatro núcleos por clúster.
Cada uno de esos núcleos Oryon integrará una unidad de ejecución vectorial VXU, una IFU para búsqueda de instrucciones, una IXU para ejecución de enteros, una REU para renombrado y retirada, la LSU para cargar y guardar datos y la MMU para la gestión de memoria.
La unidad de búsqueda y decodificación (IFU), cuenta con caché de 6 vías L1 y 192 KB y es capaz de buscar hasta 16 instrucciones por ciclo. Cuenta con tablas con distintas ramas de predicción para todo el sistema que se encarga de preparar instrucciones posibles que se ejecutarán a continuación, un sistema utilizado en prácticamente todas las CPUss modernas y que permite mejorar el rendimiento basándose en instrucciones previas y otras métricas consideradas por el sistema de predicción.

El sistema de Oryon está creado para tener una latencia de 13 ciclos cuando se predice de manera incorrecta. Junto a una decodificación de hasta 8 instrucciones por ciclo.
A nivel de las secciones de ejecución, en cálculo de Enteros soporta hasta 6 operaciones en las ALUS (Unidad Aritmético Lógica) por cada ciclo de reloj, 2 ramas por ciclo y 2 multiplicaciones por ciclo. En el cálculo vectorial en FP, cada canal tiene un ancho de hasta 128 bits, y puede gestionar hasta 4 operaciones por ciclo don datos FP32 de suma o multiplicación y también INT32 por ciclo.

Tenemos una caché L1 de 96 KB de 6 vías, con un buffer de 7 vías con soporte para 224 entradas.

La arquitectura del sistema de gestión de memoria soporta "Gránulos de Traducción de 4KB y de 64KB de tamaño, cada uno de estos gránulos hace referencia al bloque de memoria más pequeño que se puede describir, haciendo que todo lo que ocupe más que un gránulo sean conjuntos de ellos.

En cuanto a la caché L2 compartida entre los 4 núcleos (o menos) de cada clúster, tenemos 12 MB de caché de 12 vías que funciona al toda la frecuencia de los núcleos, con soporte para lecturas, escrituras y rellenos desde y hacia las cachés L1 de cada núcleo.
Se ha optimizado precisamente para los accesos de datos de la caché L1 a la L2, con una latencia media de 15 ciclos de reloj por cada dato no necesario de la cachlé L1 hacia la L2. Las operaciones se han optimizado para que se puedan realizar de un núcleo a otro núcleo y también desde un conjunto de núcleos (clúster) a otro.

Todo el sistema de CPU comparte una caché sólida de tipo SLC de 6 MB con una latencia de 26-29ns y un ancho de banda de 135 GB/s por cada dirección.
El sistema de memoria, que ya hemos comentado, soporta hasta 64 GB de memoria RAM LPDDR5x a 8.448 MT/s de 8 canales y 16 bits, con un ancho de banda de 135 GB/s, con una latencia hacia la memoria, con estas especificaciones, de entre 102 y 104 nanómetros.

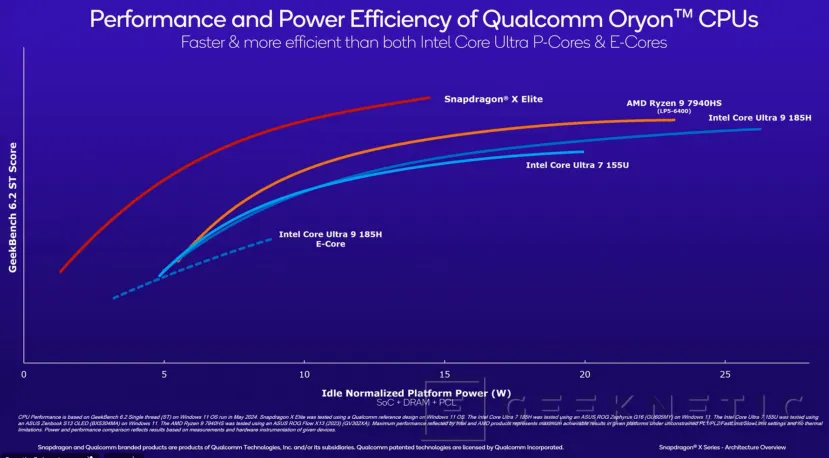
Qualcomm quiere demostrar la superioridad de su rendimiento y eficiencia mostrando los resultados si se normaliza el consumo del Snapdragon X Elite con el de procesadores Intel Core Ultra y AMD Ryzen. A mismo Consumo, el Snapdragon X Elite consigue un mayor rendimiento desde poco más de 1W hasta los 15W de consumo máximo, con los que supera a otros procesadores que pasan de 25W.
La GPU Adreno X1 integra distintas cachés y memorias locales para más rendimiento y eficiencia
Hasta ahora conocíamos pocos detalles de la GPU Adreno que integrarán los Snapdragon X Elite y el X Plus. Sabíamos que en el caso del Snapdragon X Plus, su potencia sería de hasta 3,8 TFLOPS, y en el caso del Snapdragon X Elite alcanzará los 4,6 TFLOPS y 72 GPixels/s de tasa de rellenado. Soporte para DirectX 12 era la otra característica que conocíamos, junto a un rendimiento que podía superar en un 80% a la Radeon 780M según los datos de Qualcomm.
Ahora ya sabemos que se llamará Qualcomm Adreno X1 Series y todos los detalles de su arquitectura gráfica con la que prometen un rendimiento superior a las actuales GPUs integradas de AMD.
Se trata de una GPU diseñada específicamente para ordenadores con Windows y no como una GPU general multidispositivo. Por tanto, se ha cuidado el soporte para DirectX 12.1 con soporte para SM 6.7, DirectX 11, Vulkan 1.3, OpenCL 3.0 y también con aceleración de IA mediante DirectML, con soporte nativo de IA a nivel de drivers.
Esos drivers, ya que hablamos de ellos, serán actualizables de manera independiente, de la misma forma que ocurre con las GPUs integradas de Intel o de AMD con sus drivers Radeon y Arc respectivamente. Qualcomm se compromete a un lanzamiento de una nueva versión de sus drivers gráficos para la Adreno X1 cada mes, con descarga directa desde su web y soporte para el Adreno Control Panel.

Tenemos 6 SP o Shader Proccesors que funcionan a una velocidad de hasta 1,5 GHz. Cada uno incluye 1.536 unidades aritmético-lógicas o ALUS y pueden procesar 96 texels por cada ciclo de reloj.
La interfaz de renderizado dedicada común a todos los SP que integra la Adreno X1 incluye la tecnología VRS de segunda generación, un sistema de tasa de sombreado variable basado en imágenes. Es capaz de procesar dos triángulos por cada ciclo. Cuenta también con una interfaz de unión que funciona de manera simultánea con el proceso de renderizado.
Cada SP tiene asociado un backend interno capaz de gestionar 96 fragmentos por cada Hz en filtrado MSAA y 48 píxeles. Además, cada Shader Processor también integra un módulo GMEN para lectura y escritura de memoria especializado tanto en renderizado 3D como en cómputo general para aceleración de tareas.
La unidad de gesión de la GPU (GMU) ofrece soporte para la gestión de la energía de la Adreno X1 y también virtualización de la gráfica, pudiendo gestionar hasta 8 máquinas virtuales independientes con su propia GPU virtual.

Pasamos ahora a ver en detalle qué esconde cada Shader Processor o "SP" de los 6 que integra la X1, dotado de los propios núcleos de ejecución y una caché de instrucciones compartida para todo el SP. Cada uno de estos SP está dividido en varias partes, desde las distintas ALUs (dos de 128 x 32 bit y dos de 256 x 16 bit).
Una ALU de cada tipo se integra dentro de lo que se considera como uSPTP, y cada SP lleva dos de estas líneas de sombreado y texturas.
En cada uSPTP se incluye su propia memoria dedicada de 192 KB, con una unidad de carga y almacenamiento de datos. Tenemos un total de 12 uSPTP en una GPU completa Adreno X1.

Hace más de 10 años, la arquitectura HSA se hizo un hueco en el mercado, permitiendo que la CPU y la GPU trabajaran con los mismos datos al compartir el acceso a los mismos datos. De hecho, Qualcomm fue una de las primeras compañías que fundaron la HSA Foundation.
Hoy en día este tipo de sistemas son lo común y cobran aún más sentido al tener cada vez más componentes en un procesador. De una CPU a GPU, pasamos a un conjunto de módulos que en estos Snapdragon X Series comparten acceso a la memoria del sistema. Tanto la CPU como la GPU y la NPU, además de otros elementos, comparten acceso a la memoria del sistema y tienen 6 MB de caché en el propio SoC.
La Adreno X1, por tanto, también tiene disponible la memoria del sistema, con acceso al MCU o controlador de memoria que se comunica con la DRAM, además de la mencionada caché de 6 MB.

La GPU cuenta también con su propia caché L2, con 1 MB unificado compartido con todos los SP como se piodía ver en el esquema general de hace un par de imágenes. Adicionalmente, cada grupo formado por 2 SP tienen acceso a 128 KB de caché propia denominada Cluster Caché.
Todo esto se suma a cachés más pequeñas asociadas a distintos elementos como las instrucciones de sombreado o para almacenar datos de texturas de manera local.
Además de las cachés y el acceso a la memoria general, la GPU Adreno cuenta con una memoria interna de alto ancho de banda exclusiva para ella denominada GMEM. Ofrece 3 MB de SRAM con un ancho de banda de 2 TB/s. Esta memoria se puede utilizar para distintos elementos del proceso de la GPU y no solo caché, ya sean tareas de renderizado o de cómputo general.
Permite evitar accesos a la memoria del sistema, consiguiendo una mayor rapidez y ancho de banda, reduciendo también la latencia y consiguiendo más eficiencia energética.

En cuanto a tecnologías propias soportadas por este hardware, destaca la tecnología Qualcomm FlexRender, un sistema que es capaz de cambiar entre modos de renderizado para cada superficie concreta en un entorno 3D. Es el propio driver el que lo gestiona y decide qué modo es el más óptimo para aplicar en cada momento.
Hay tres modos de renderizado soportados: el modo directo, que renderiza de manera tradicional y es compatible con todos los juegos y programas actuales existentes. Luego está el modo conjunto o agrupado "Binned Mode", que divide cada fotograma en pequeños trozos denominados "baldosas" y se renderizan directamente en la memoria GMEM integrada en la GPU.
Este modo agrupado, al trocear la escena y pasarla a la memoria interna para su renderizado, consigue más eficiencia al no necesitar acceder a tantos datos desde fuera de la propia GPU.

Finalmente, el mono "Binned Direct Mode", o "modo agrupado directo", es una variante que combina los modos directo y el agrupado, mediante un sistema de pasadas realizadas en paralelo antes de pasar al modo directo y centrando el renderizado en los elementos necesarios para reducir la carga de trabajo.
Rendimiento y eficiencia de la Snapdragon Adreno X1
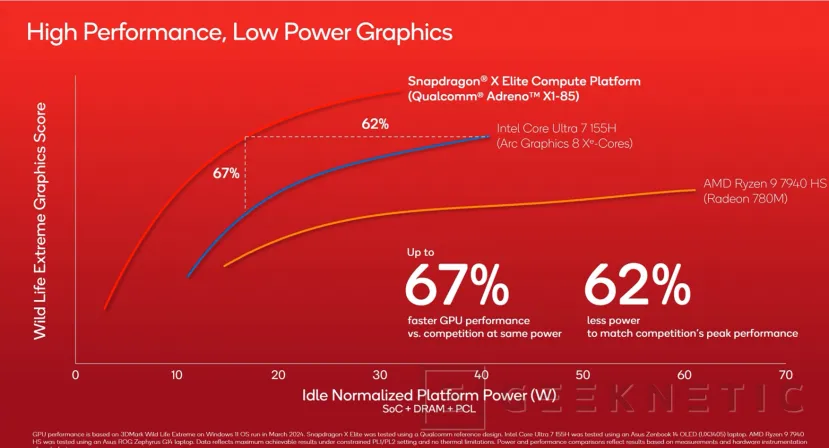
Qualcomm ha desvelado algunos detalles más sobre el rendimiento y eficiencia de su GPU Qualcomm Adreno X1. En concreto, en la siguiente gráfica podemos ver la Adreno X1-85 que integra el Snapdragon X Elite en comparación con la Intel Arc de 8 Xe Cores del Intel Core Ultra 7 155H y de la Radeon 780M del Ryzen 9 7940 HS.
Según los datos de Qualcomm, al mismo nivel de consumo, la Adreno X1-85 es capaz de ofrecer hasta un 67% más de rendimiento.
En caso de que igualemos rendimiento, la Adreno X1 puede ofrecer el mismo rendimiento que la Intel Arc de 8 Xe Cores con un 62% menos de consumo.
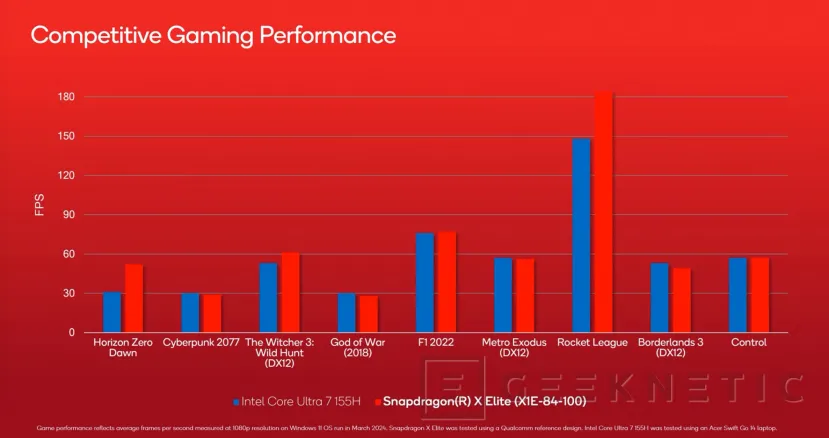
El rendimiento extra se traduce en más prestaciones en juego. Será una GPU integrada con las limitaciones que eso supone, lejos de las gráficas dedicadas actuales. Pero ya hace tiempo que Intel y AMD ofrecen integradas capaces de ejecutar juegos sin muchos problemas a resoluciones moderadas.
Por eso, los datos de la Adreno X1 de los Snapdragon X Series son bastante prometedores, consiguiendo superar los 180 FPS en juegos como Rocket League, o superar los 60 FPS en títulos como The Witcher 3 Wild Hunt o F1 2022.
Está claro que será capaz de superar a las GPU actuales de Intel y AMD, pero estas ya preparan sustitutas con las GPus de Lunar Lake y de los Ryzen AI 300. En cualquier caso, conseguir este nivel de rendimiento con un SoC con nueva arquitectura es todo un logro en un mercado que Intel y AMD dominan desde hace muchos años.
La Hexagon NPU promete más rendimiento y eficiencia energética para IA en Copilot+
Si hay algo que se está llevando gran parte del protagonismo, al menos en las presentaciones que hacen empresas como Qualcomm, Intel o AMD, es sin duda la NPU o Neural Processing Unit. En el Computex 2024 hemos visto a los CEOs de los principales fabricantes de SoCs hablar de este elemento orientado al procesamiento de tareas de inteligencia artificial en local y con la mayor eficiencia posible, con el abrazo de Microsoft y sus Copilot+ PCs con Windows como plataforma (no por nada, Satia Nadella, CEO de Microsoft, tuvo un mensaje en todas y cada una de las keynotes de los tres fabricantes de CPUs).
Las NPU, si bien no suelen ser más potentes que las GPU en potencia bruta para tareas de IA, sí que son capaces de ofrecer aceleración específica para estos procesos con un consumo muy inferior, dejando libres a las CPU y a las GPU para otras tareas propias.

Qualcomm ya nos enseñó de lo que eran capaces las NPU de los Snapdragon X Elite y X Plus, y ahora vamos a ver en detalle cómo está diseñada y como funciona.

La NPU toma el nombre de la gama Hexagon que la compañía lleva integrando desde hace 20 años en sus SoCs para distintos tipos de tareas. Inicialmente conocido como DSP (Digital signal processing) y más tarde como "Procesador", antes de la popularización de la IA a gran escala, se dedicaban al procesamiento específico de audio e imagen con un diseño orientado a procesamiento escalar primero, y luego añadiendo procesamiento vectorial en los últimos 10 años.
La llegada de la IA ha hecho que los DSP Hexagon evolucionen a lo que hoy se conoce como NPU con su Hexagon NPU. Seguimos teniendo distintas partes orientadas al procesamiento escalar y vectorial, pero se ha integrado aceleradores Tensor optimizados para el procesamiento matricial, clave en la ejecución de tareas de Inteligencia Artificial.

Por tanto, en la NPU Hexagon del Snapdragon X Elite y X Plus lo podemos dividir en 5 partes de las cuales 3 de ellas son los módulos encargados de los distintos tipos de operaciones. Hay acceso directo de los distintos hilos a la caché DDR y a las memorias compartidas de los núcleos.
- Así, tenemos la zona de procesamiento escalar para tareas de control de flujo del procesamiento y también tareas generales. Esta parte es capaz de gestionar 6 hilos simultáneos.
- Por otro lado, la zona de procesamiento vectorial para tareas de procesamiento paralelo de datos, utiliza el juego de instrucciones HVX (Hexagon Vector eXtension). Cuatro hilos en total se encargan de esta tarea.
- Finalmente, en la zona de procesamiento Matricial se procesan las instrucciones HMX (Hexagon Matrix eXtension) para la multiplicación de matrices con los aceleradores Tensor de enteros y PF16 (precisión simple de 16 bits)

Otra parte de la NPU Hexagon es el de la memoria Vector TCM (memoria estrechamente acoplada). Se trata de un sistema de memoria de caché L1 desarrollada específicamente para trabajar con los tipos de datos de Qualcomm HMX y HVX que, tal y como hemos visto, hacen referencia a las instrucciones Hexagon Matrix eXtension y Hexagon Vector eXtension).
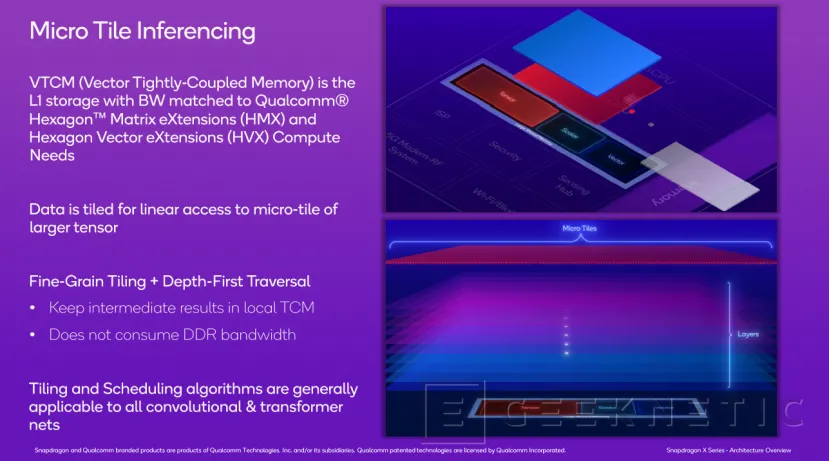
A esta memoria, por tanto, además del propio módulo de procesamiento de memoria, solo tienen acceso el módulo de procesamiento vectorial y el de procesamiento matricial. No obstante, la memoria está dividida en pequeñas "baldosas" para optimizar el acceso a los datos desde el acelerador Tensor de procesamiento matricial más orientado a tareas específicas de IA.
El procesado típico de escalares también se ha potenciado, aunque puede parecer algo contradictorio teniendo en cuenta las necesidades de la IA, lo cierto es que disponer de más potencia en la parte de la NPU dedicada a este tipo de procesamiento permite potenciar la gestión de los flujos de datos hacia las distintas partes. No nos olvidemos que, tal y como hemos descrito al principio de esta sección, el procesador escalar es el encargado de dicho control, además de tareas más generales.
Soporta 6 hilos simultáneos e incluye distintos niveles de predicción de instruciones, con una sincronización hardware rápida y acceso directo al sistema de procesado de memoria.

El procesamiento de IA utiliza distintos tipos de datos con más o menos bits dependiendo de las necesidades y tipo de operación. A mayor número de bits se consigue más precisión, pero el consumo y necesidades de cómputo aumentan.
Las tareas que necesitan procesamiento de operaciones de pocos bits consiguen más rendimiento, menor uso de memoria y de ancho de banda, y también necesitan menos energía. Así que la idea en la que trabajan todos los fabricantes que están desarrollando NPU, como es el caso de esta Hexagon, es la de utilizar distintas técnicas de aprendizaje o el uso de precisiones mixtas en vez de fijas para potenciar la precisión utilizando un número reducido de bits.
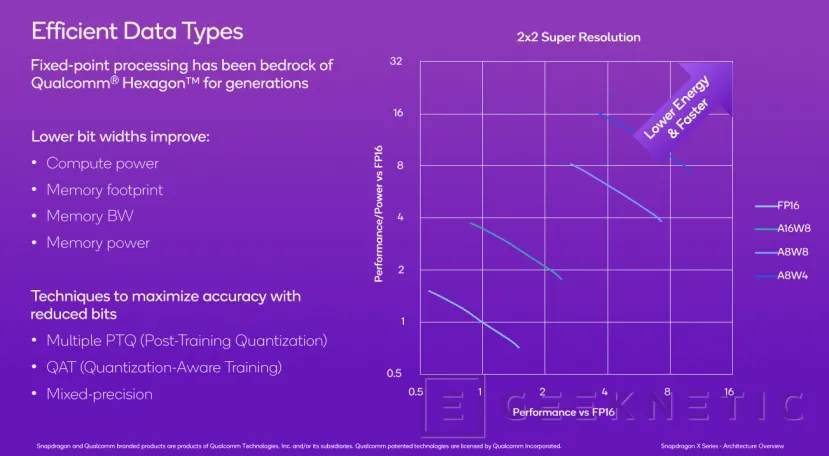
Así, lo que utilizando instrucciones FP16 conlleva altas necesidades de rendimiento y energía, en otro tipo de datos combinados como A16W18, A8W8 o A8W4 se consigue mayor rapidez con menor energía, multiplicando el rendimiento por vatio.
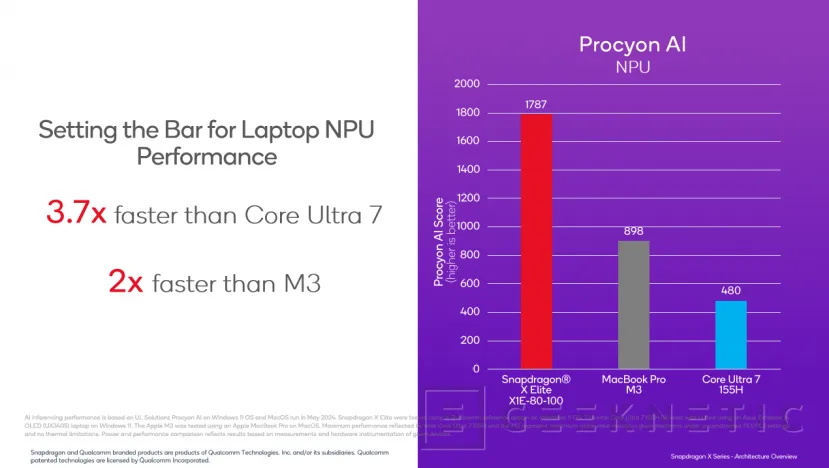
En cuanto a rendimiento, los datos de Qualcomm comparan el uso de esta NPU de los Snapdragon X Series con la de los Macbook Pro con el chip Apple M3 y con portátiles dotados con el Intel Core Ultra 7 155H y su NPU. La NPU Hexagon ofrece 45 TOPS ella sola.
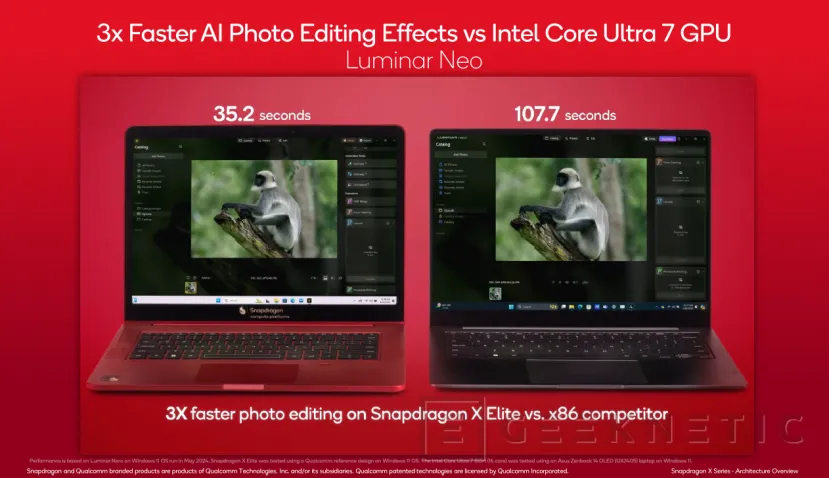
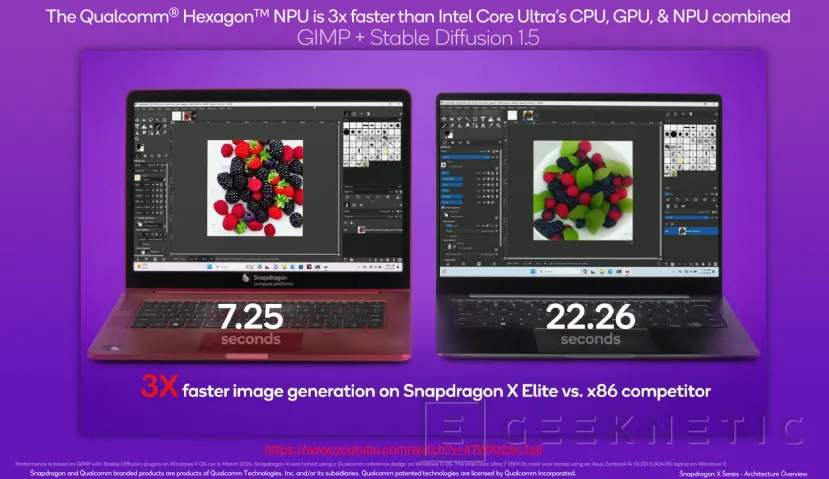
Según la compañía, la NPU Hexagon del Snapdragon X elite X1E-80-100 ofrece un rendimiento del doble respecto del Apple M3 y 3,7 veces superior al de la solución con Intel Meteor Lake.
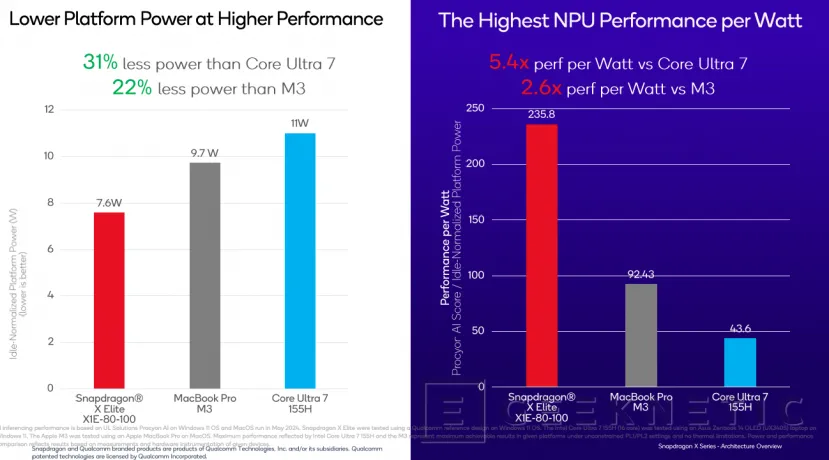
Sin embargo, de lo que más presume Qualcomm, tal y como dejaron claro en el Computex 2024, es de su alta eficiencia. Consiguen un 22% menos de consumo que el Apple M3 y uun 31% menos que el Core Ultra 7 155H, convirtiéndose en la NPU con mayor rendimiento por Vati: 5,4 veces mejor que el Core Ultra 7 y 2,6 veces superior al del Apple M3.
También han compartido algunos resultados de rendimiento en algunos test de MLPerf Mobile v4.0.

Los Snapdragon X Series tendrán que enfrentarse a los Ryzen AI 300 y los Intel Lunar Lake

Está claro que el salto de rendimiento y especificaciones será impresionante, pero enfrente no tendrá a los actuales Intel Metor Lake o los AMD Phoenix: Sus competidores también han mostrado algunas novedades en el Computex 2024 en forma de los nuevos AMD Ryzen AI 300 o los Intel Lunar Lake, y prometen un salto considerable respecto de las pasadas generaciones con las que se compara a los Snapdragon X Elite y X Plus. Las mejoras estarán orientadas a CPU, GPU y también a la NPU, un elemento que abre un nuevo campo de batalla con la IA como fondo.
Todo parece indicar que la lucha será encarnizada, pero también que Qualcomm podrá competir de tú a tú con los dos principales fabricantes de procesadores del sector.

Para conseguirlo, más allá de las especificaciones y características de sus chips, es importante también contar con el soporte de los principales fabricantes de portátiles, y según hemos podido comprobar en el Computex, los Snapdragon X Elite y Snapdragon X Plus estarán presentes en más de 20 modelos de distintos fabricantes con la paltaforma de Microsoft Copilot+ PC para su lanzamiento, por lo que el comienzo parece prometedor.
Sin duda, se avecinan tiempos muy interesantes en el mercado de portátiles, y estamos deseando comprobar de lo que son capaces estos nuevos SoCs.
Fin del Artículo. ¡Cuéntanos algo en los Comentarios!








