


Groq ofrece una unidad LPU capaz de acelerar la respuesta en lenguajes de grandes dimensiones como GPT o LLAMA
por Juan Antonio SotoAunque principalmente conocemos las soluciones de los principales fabricantes para Inteligencia Artificial, hay una gran cantidad de empresas que también están detrás de diseños y chips especializados. El chip de Groq LPU es capaz de ofrecer una gran velocidad en inferencia, una velocidad que es crucial para poder ofrecer respuestas rápidas a los usuarios que demandan preguntas en modelos de lenguajes grandes como Llama o GPT.
Este chip Groq, denominado LPU (Language Proessing Unit) está diseñado para estos modelos y ofrecer unas velocidades en inferencia más rápidas. La inferencia es la capacidad de ofrecer tokens de respuesta por parte de la Inteligencia Artificial, cuantos más tokens (palabras) más completa será. Este chip solo tiene un núcleo y está basado en la arquitectura Tensor-Streaming Processor, capaz de alcanzar los 750 TOPS en INT8 y 188 TeraFLOPS en FP16. También es capaz de realizar multiplicación de matrices de 320x320 y cuenta con 5120 ALUs (unidades aritmético-lógicas) vectoriales.
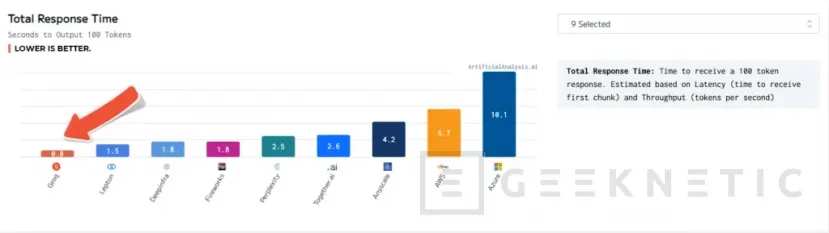
Es capaz de ofrecer hasta 80 TB/s de ancho de banda gracias a sus 230 MB de SRAM funcionando en local. Esto permite ofrecer hasta 480 tokens por segundo en Mixtral 8x7B, 300 token por segundo en Llama 2 70B y hasta 750 tokens por segundo en Llama 2 7B. Según los datos de LLMPerf, este chip es capaz de superar en rendimiento de token y latencia a las actuales soluciones de proveedores en la nube.
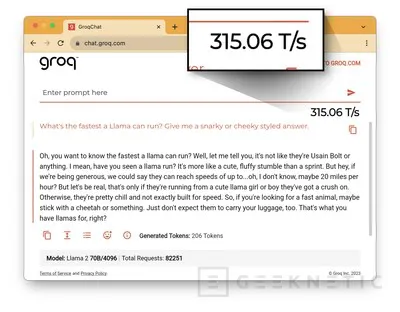
Con este chip se puede acelerar la respuesta de otros lenguajes como GPT en su versión 3.5 que actualmente ofrece hasta 40 tokes por segundo, una cantidad que puede ser superada con creces gracias a la ayuda del hardware de Groq.
Fin del Artículo. ¡Cuéntanos algo en los Comentarios!








