


¿Quién es Tim Wilson y Por Qué le Entrevistamos?
Durante mi asistencia al Intel Innovation en San José, California, la semana pasada tuve la ocasión de entrevistar a Tim Wilson, Vicepresidente de Intel para el Grupo de Ingeniería de Diseño y Director General de Diseño de SoCs en Intel.
Tim es uno de los máximos responsables del desarrollo de Meteor Lake, y como tal era la persona ideal con la que profundizar en cómo está hecha esta nueva arquitectura, los retos que han tenido que superar y lo que supone para el consumidor y también la industria.
Antes de leer la entrevista completa, te recomiendo que eches un vistazo a nuestro artículo sobre Meteor Lake, donde te detallamos todo sobre esta nueva arquitectura híbrida. Tenemos otro artículo dedicado a los gráficos que integra Meteor Lake y otro al nuevo nodo Intel 4 que se estrena con esta arquitectura.

Os dejo la entrevista completa a continuación:
Entrevista a Tim Wilson de Intel
*Nota: la entrevista ha sido adaptada para dar coherencia y legibilidad en un formato escrito dentro del contexto de los temas que se tratan.
GEEKNETIC: ¿Puedes explicarme cuál es tu rol en Intel?
Tim: Durante los últimos años he liderado el desarrollo de Meteor Lake, que es nuestra próxima arquitectura de cliente. Desde definición de la arquitectura hasta validación de silicio y su entrega.
GEEKNETIC: Entremos de lleno a hablar precisamente de Meteor Lake. En tu presentación usaste como ejemplo la reproducción multimedia a la hora de comparar el diseño en bloques de Meteor Lake en comparación a Raptor Lake, y nos explicabas cómo en ese caso, si eso es lo único que se está haciendo con el PC, no se necesita activar el bloque de gráficos ni el bloque de cómputo porque es capaz de hacerlo funcionar todo en el bloque del SoC. Entonces, si el PC solo está haciendo reproducción multimedia, ¿puedes indicarme cuales son las mejoras de consumo en ese caso con respecto a Raptor Lake?
Tim: En general, el SoC de Meteor Lake, es el SoC de menor consumo que hemos hecho nunca. Es por eso por lo que esperamos ver un 40% o un 50% menos de consumo en una amplia gama de tareas. No obstante, pronto dispondréis de productos en vuestras manos, que podréis probar y tomar mediciones por vosotros mismos. También compartiremos más detalles. Dejaremos algo del suspense para el lanzamiento.
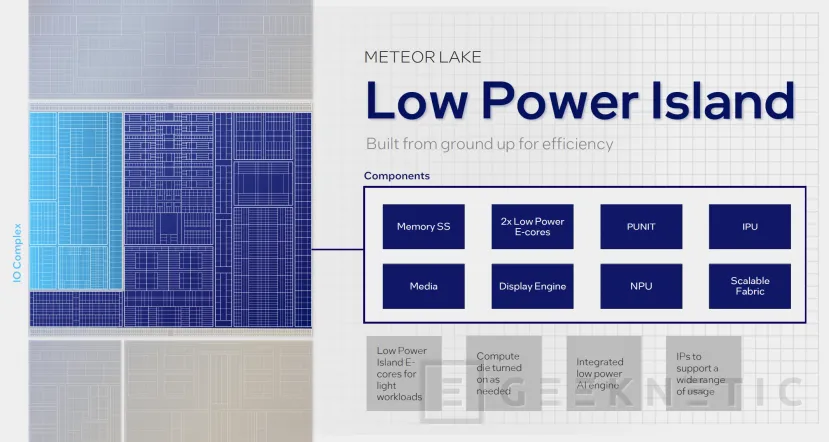
GEEKNETIC: Teniendo en cuenta que Meteor Lake es capaz de sostener la reproducción de vídeo sin encender el bloque de gráficos ni el bloque de cómputo. ¿Tendría sentido hacer procesadores sin el bloque de gráficos, por ejemplo, para portátiles gaming que ya de por sí tienen gráficos dedicados? Igual que hacéis con los procesadores de sobremesa de serie F.
Tim: Sí, es un gran concepto. Desde luego podemos visualizar el hacer algo así. Creo que hemos creado Meteor Lake con distintos sabores. No obstante, uno de los pilares más importantes de Meteor Lake es que entregamos el doble de la potencia gráfica integrando nuestros gráficos dedicados directamente en el chip para esa experiencia de gráficos de dedicados en portátiles finos y ligeros. Por tanto, antes de crear un modelo de procesador sin gráficos, te sugeriría tomar Meteor Lake y usarlo como un portátil gaming con sus gráficos integrados. De todas formas, es cierto que el concepto de tener bloques y poner y quitar y crear distintas configuraciones con mayor facilidad, es una de las ventajas de una arquitectura desagregada.
GEEKNETIC: ¿Y ahora podrías entrar en un poco más de detalle en las diferencias técnicas entre los E-Cores convencionales y los E-Cores de bajo consumo?
Tim: Para empezar en Meteor Lake, los E-Cores del bloque de cómputo y los E-Cores en el bloque del SoC, son la misma arquitectura. La diferencia es que los hemos optimizado para distintos propósitos. Los E-Cores del bloque de cómputo están optimizados para un rendimiento superior y tareas multihilo, mientras que los E-Cores en el bloque de SoC, están específicamente optimizados para bajo consumo y tareas que no requieren de unas completas capacidades de cómputo de nuestros P-Cores y E-Cores en el bloque de cómputo. Por tanto, desde el punto de vista de la arquitectura son iguales, pero desde el punto de vista de la optimización y rendimiento por vatio son diferentes.
GEEEKNETIC: ¿Podrías indicarme otros ejemplos de tareas que pueden ser asignadas a los E-Cores de bajo consumo (en el SoC) y permanecerán en ellos?
Tim: Claro, puedo darte otros ejemplos. Realmente habrá una amplia gama de tareas como, chequeos que hace el sistema en segundo plano, tareas de seguridad como escaneos de seguridad, reproducción multimedia, streaming, algunos modos de navegación por internet. Esto al final dependerá de las características de la tarea, sus requerimientos con respecto la intensidad de cómputo y caché necesarias. Este tipo de cosas determinarán si la tarea se cubre completamente en el SoC o si se migra al bloque de cómputo. Pero por supuesto la intención es, y la razón por la que usamos la reproducción multimedia y el streaming es que es una de las cosas más comunes que todo el mundo hace con el PC. Por lo tanto, para muchas tareas comunes que hacemos a diario, verás que estos núcleos del SoC entrarán en juego.
GEEKNETIC: ¿Podrías explicarme cómo de grandes son diferencias entre los P-Cores y E-Cores de Raptor Lake con respecto a Meteor Lake?
Tim: Tanto los P-Cores como los E-Cores en Meteor Lake tienen algunas mejoras en sus microarquitecturas desde nuestra última generación: Raptor Lake. No obstante, tenemos el nuevo proceso Intel 4 que estamos lanzando con Meteor Lake y generalmente cuando introducimos un nuevo proceso tendemos a tomar menos riesgo en la parte de arquitectura. Y entonces una vez tenemos un proceso estable, tendemos a realizar mayores saltos al mejorar nuestras arquitecturas. Por tanto, como este es un nuevo gran nodo para nosotros y estamos obteniendo los beneficios de eficiencia de Intel 4, hemos realizado menos cambios en la arquitectura de los núcleos por lo que son muy similares en cuanto a arquitectura con respecto a los E-Cores y P-Cores de Raptor Lake.
GEEKNETIC: ¿Podrías hacerme una lista de más a menos con respecto a los mayores contribuyentes al rendimiento por vatio en Meteor Lake?
Tim: El primero sería los grandes cambios que hemos hecho a lo que llamamos nuestro chasis SoC. Los cambios arquitecturales para separar las partes del chip que de cómputo intensivo y volver a desarrollar las estructuras para un ancho de banda de memoria superior. Esa fue una de las grandes formas en que fijamos los cimientos para que pudiéramos operar de forma mucho más eficiente en muchas tareas. Segundo, diría que la creación y la implementación de los E-Cores de bajo consumo en el bloque del SoC, de forma que están directamente unidas a la estructura del SoC y separados de el bloque de cómputo. Esas son una gran parte de las mejoras en eficiencia en muchas tareas. Y tercero, diría que el simple hecho de separar los bloques, de forma que podemos optimizar diversos chips para el proceso de fabricación que tiene las características que mejor ban con esos chips, eso también tiene un gran impacto.
GEEKNETIC: Vuestra tecnología de empaquetado Foveros 3D os permite desagregar el diseño y fabricar cada bloque en el proceso y fábrica más apropiada para la geometría del bloque y sus necesidades. De hecho, el bloque de SoC de Meteor Lake está fabricada en TSMC. ¿Por qué no se ha elegido Intel 4 en este caso?
Tim: Excelente pregunta. Cuando miras el amplio rango de componentes que tiene un SoC moderno hoy en día, con sus distintas geometrías de transistores, ves que no todos requieren los mismos beneficios de las características de cómo hace los transistores cada proceso de fabricación o nodo. Tomemos por ejemplo los P-Cores, requieren los transistores más rápidos y de mayor rendimiento que se pueda obtener. Pero tenemos distintos componentes dentro del SoC como por ejemplo el componente de conectividad, que siempre está encendido y a la escucha.
Éste no es un componente intensivo con respecto a su rendimiento, pero tiene muy bajo consumo, pocas fugas de energía. Esto es muy distinto de, por ejemplo, los P Cores. Y tenemos otros componentes que requieren de transistores de alto voltaje para poder gestionar las necesidades de conmutación eléctrica de la plataforma. Por otro lado, las capacidades de cómputo de IA se benefician de los transistores más avanzados en el nodo más avanzado posible, y eso es lo que hemos priorizado en Meteor Lake.
Hemos hecho el bloque de cómputo en Intel 4 mientras, otros bloques tienen distintas características que van mejor en otros procesos de fabricación, por lo que hemos usado un proceso de fabricación distinto para ellas.

GEEKNETIC: Siguiendo esta misma conversación, el bloque IO se ha hecho en TSCM N6. ¿Es la razón técnica o es cuestión de coste?
Tim: Diría que como ingeniero, los problemas a resolver más interesantes son los técnicos. Los aburridos son donde tenemos que solventar los costes y cosas así. Pero claro, obviamente eso se tiene que tener en cuenta en algún momento también. Pero sí, el bloque IO hecho en TSMC N6, con transistores del tipo que requieren el alto voltaje de un proceso más antiguo y estable, con muchos tipos de chips que ya se ha demostrado que funcionan en ese proceso. Podemos aprovecharnos de eso de una forma efectiva y a un menor coste.
GEEKNETIC: Entonces después tenemos el bloque base, que hace de intermediador sobre el cual se colocan el resto de los bloques. ¿En qué proceso está hecho?
Tim: Es un nodo de Intel, es lo que llamamos el nodo 1227, que probablemente no te sonará mucho porque no es un nodo que haya tenido mucha publicidad. Esto es como has dicho un intercambiador pasivo, es decir, que no hay dispositivos activos en ese nodo. Básicamente nos sirve para de algún modo darnos los “cables” entre los bloques que se ponen encima y sirve como una base con sus micro conectores.
GEEKNETIC: ¿Hay limitaciones que traiga Foveros 3D con respect al nodo que se puede usar?
Tim: No hay limitaciones y ese era uno de nuestros requisitos fundamentales desde el principio. Como ves los 4 bloques que hacen Meteor Lake han sido hechos en 3 procesos de fabricación distintos. Queremos tener la habilidad de seleccionar el nodo apropiado para cada bloque. Esto es algo que evolucionará con el tiempo. Entonces las características del intermediador o Foveros 3D significa que necesita poder funcionar con cualquier bloque en cualquier nodo.
GEEKNETIC: ¿Pero alguna limitación habrá no? Por ejemplo, no podrás usar un bloque en un proceso muy viejo a 60nm, por ejemplo, sobre el bloque base o intermediador.
Tim: Eso es más una limitación del nodo en que se ha hecho el bloque, y no del intermediador. Dicho de otra manera, el intercambiador o capa base puede funcionar con cualquier bloque que sea compatible con el ensamblado Foveros. Si tienes un proceso más viejo que no es compatible con Foveros, entonces no funcionará, pero eso no es algo que dependa de la capa base o intermediador.
GEEKNETIC: Sin embargo, entiendo que según se van mejorando los nodos y los procesos de fabricación, también se tendrá que actualizar el intermediador para que sea compatible, ¿no?
Tim: La capa base o intermediador está unida a los bloques de encima de forma muy cercana. Cada vez que hago una nueva configuración, creo una nueva capa base. Hemos tenido esto en cuenta en el proceso de desarrollo y la capa base es muy flexible y relativamente fácil para nosotros convertirla en una configuración única para soportar los requisitos de los bloques que están sobre ella. Verás que según vayamos lanzando la familia Meteor Lake hay múltiples versiones y es bastante simple para nosotros.
Algo a tener en cuenta es que somos los únicos que pueden hacer esto, es decir, que podemos tomar chips hechos en procesos de fabricación de distintas compañías. Diferentes procesos de distintos lugares y ponerlos juntos en un único paquete. Solo Intel puede hacer eso hoy en día.

GEEKNETIC: Ha habido cierta preocupación por parte de nuestros lectores, ahora que ya hemos publicado nuestros artículos sobre Meteor Lake. Por lo visto a nuestro público le recuerda a cuando AMD empezó a trabajar con el Infinity Fabric. Hubo algunas quejas en aquel momento con cuellos de botella y cosas así. ¿Podrías decirme algo sobre las desventajas que puede tener el uso de chiplets con Foveros en referencia a latencia en acceso a memoria, TDP o regulación de potencia?
Tim: Sí, esa es una gran pregunta. Cuando decidimos desagregar la arquitectura, tuvimos muy claro desde el principio que en todos los puntos donde queríamos hacerlo, tenían que tener interfaces de gran ancho de banda en la arquitectura. Y esta es precisamente el gran desafío de una arquitectura desagregada. Como se maneja el potencial para de desagregar algo y obtener todos sus beneficios sin darle de vuelta todo a lo que llamamos “fricción de transferencia” moviendo los datos entre los bloques y desperdiciando energía.
Por lo tanto, hay unas pocas características clave todo interfaz de un bloque a otro necesita tener. En primer lugar, necesita un hilado muy fino y unas conexiones muy pequeñas, porque estás físicamente limitado en la cantidad de espacio disponible para mover esta cantidad de datos de un lado para otro. En segundo lugar, necesita tener una alta eficiencia energética. Se necesita mover todos esos datos con muy pocos requisitos energéticos, para no tener que devolverle potencia (desde los bloques) con el hecho de mover los datos. Toda potencia energética usada en mover datos es energía desperdiciada en los bloques activos. En tercer lugar, tengo que poder hacer esto a una latencia que no me cuesta rendimiento en general. Estas han sido las cosas que han limitado hasta ahora a los fabricantes de chips, desagregarlos en el pasado y para nosotros la clave para desbloquear todo eso es la tecnología de empaquetado avanzada Foveros.
Esto es justo lo que nos aporta Foveros, unas interconexiones y un hilado 10 veces más denso que nuestro empaquetado tradicional. Y podemos hacerlo a una latencia que cuesta menos de un 1% del rendimiento global. Y estás exactamente en lo cierto, esos son los problemas que hemos tenido que solventar y por lo que la tecnología de empaquetado Foveros 3D es una parte clave para desagregar.
Es realmente el ingrediente secreto que nos permite hacerlo y mantener los beneficios de un diseño monolítico mientras gozamos de los beneficios de la desagregación. Además, si nos fijamos en fotos de la CPU de Meteor Lake y dependiendo del ángulo parece monolítico y no podrías distinguirlo, y realmente tienes que fijarte mucho para apreciar la “costura” entre los bloques. Es bastante curioso de ver.

GEEKNETIC: En las explicaciones y ejemplos que se nos han dado, hay circunstancias en que, si hay un trabajo intensivo realizándose en el bloque de cómputo, por ejemplo, en los P-Cores, y tienes otro trabajo poco intensivo, como reproducción multimedia, que podría ejecutarse únicamente en el bloque SoC con los E-Cores de bajo consumo, es mejor mantenerlos en los E-Cores convencionales del bloque de cómputo. Se justifica todo ello porque ya que está el bloque de cómputo encendido es mejor usarlo. Sin embargo, el bloque SoC también está en funcionamiento, ¿puedes explicar de forma un poco más extensa por qué sigue siendo mejor mantenerlo en el bloque de cómputo?
Tim: Piensa que el bloque SoC, es algo así como el bloque que sobre el que se cimenta todo. El SoC siempre tendrá cosas funcionando. No hay tareas en que el bloque de cómputo está encendido y el bloque del SoC está apagado. Tiene la gestión de entrada y salida de datos, tiene parte de los engranajes base sobre el que se apoya lo demás, por lo que el SoC siempre está encendido.
Cuando se están realizando tareas donde no necesitas la potencia computacional del bloque de cómputo o los gráficos, puedo apagar estos bloques completamente. Y esto me lleva a un nivel de eficiencia energética mucho mejor.
En general tanto si tenemos 1 tarea o varias, cuando dicha tarea requiere mayor intensidad computacional de la que los E-Cores de bajo consumo pueden sostener, para eso es para lo que tenemos el bloque de consumo, por lo que moveremos esas tareas al bloque de consumo, tanto a los E-Cores como a los P-Cores. Entonces una vez que encendemos el bloque de cómputo y obtenemos toda la capacidad computacional hay una gran cantidad de energía que va al bloque entero, no solo a los núcleos. Por tanto, es mejor hacer funcionar todas las tareas en esos núcleos de alto rendimiento porque el bloque ya está encendido y acabar esas tareas antes. Y después volver a apagarla en lugar de repartir las tareas los E-Cores del SoC.

GEEKNETIC: ¿Significa entonces que los E-Cores de bajo consumo del bloque del SoC se pueden apagar por completo, aunque no puedas apagar todo el bloque SoC?
Tim: Sí, en el bloque del SoC, se pueden apagar independientemente los componentes, tanto si es la NPU, como los E-Cores, Reproducción, etc.
Imaginemos que tenemos ya una tarea que no es posible ejecutarla en los E-Cores del SoC y me obliga a migrarla al bloque de cómputo, y tenemos otra tarea que es de bajo consumo. Supongamos que los E-Cores del bloque de cómputo consumen el doble que los E-Cores de bajo consumo del SoC, pero también completan las tareas en la mitad del tiempo. Por tanto, es la misma energía hacer funcionar esta segunda tarea en uno o en otro. Entonces existe esta ecuación en que si puedo hacer la tarea más rápido porque ya estoy gastando energía en tener el bloque de cómputo encendido igualmente, se convierte en una ecuación incremental que hace que Thread Director haga los cálculos de cuánta energía se tiene que gastar o cuánto me va a costar. Así es como Thread Director ayuda a guiar para ese tipo de decisiones. En general en el sistema, con todo lo demás que hay funcionando, es más eficiente hacer funcionar esta tarea en estos núcleos o en estos o en estos otros.
También hay ciertos requisitos con respecto a la experiencia. Puede que sea más eficiente poner unas tareas en los E-Cores de bajo consumo del SOC, pero como usuario también esperas cierto esperas un cierto rendimiento del equipo. En ciertas ocasiones es mejor moverlo al bloque de cómputo por lo que tienes la mejor experiencia y sacrificas algo de energía. Al final esperas que el equipo se sienta fluido.
GEEKNETIC: ¿Pero entiendo que muchas decisiones al final dependerán del sistema operativo?
Tim: Se requiere una relación simbiótica, mucho más de la que se ha necesitado jamás. El sistema operativo tomará la mejor decisión que pueda, pero realmente no tiene mucha información sobre el hardware. Ahí es donde entra Thread Director y dice: estas son las características que necesitas saber sobre el hardware para tomar la decisión correcta sobre dónde colocar esta tarea.
GEEKNETIC: El bloque de gráficos y el SoC están fabricados en TSMC, y mientras es genial que podáis combinar chiplets de distintos procesos y fabricantes, ¿es la decisión de eso técnica o financiera?
Tim: Ha sido principalmente una decisión de desarrollo de arquitectura. Esto es un nuevo nivel de libertad que tenemos a la hora de desarrollar un producto. Mirándolo a grosso modo: ¿Qué características son las que quiero invertir en esta generación de producto? ¿Y qué significa esto para las decisiones que tomo con respecto a los nodos?
Imagino que según pasa el tiempo iremos tomando diferentes decisiones basadas en las prioridades de la arquitectura y el desarrollo de generación en generación. Un bloque estará hecho en esta fundición esta generación y será en una fundición distinta en otra generación. No creo que se pueda ver nada con respecto a la parte financiera, es más sobre qué decisiones tenemos que tomar en la arquitectura y en el desarrollo basándonos en una imagen muy compleja donde estamos tratando compensar las distintas características del producto en esa generación.
GEEKNETIC: Y me pregunto: ¿Cuánto de esto es realmente el hecho de demostrar que sois capaces de hacer esta desagregación?
Tim: Bueno, nos has visto hablar sobre Meteor Lake como nuestro cambio en arquitectura más grande de los últimos 40 años. Esto es exactamente lo que hemos aportado, tanto si es desagregación, el empaquetado Foveros 3D, introducir la IA, la redefinición del NCORE de nueva generación, los E-Cores de bajo consumo … Todo esto ha sido un gran ejercicio de demostrar el concepto y tener pruebas.
GEEKNETIC: Se que no nos puedes hablar de productos no anunciados y que no vamos a obtener respuesta sobre si los próximos procesadores de sobremesa serán Raptor Lake-S Refresh o Meteor Lake. Sin embargo, las pasadas 2 arquitecturas fueron primero para sobremesa y sabemos que esta arquitectura vendrá primero a portátiles. Dentro de lo que estás autorizado a compartir conmigo, ¿puedes darme alguna pista?
Tim: Sí, siempre hemos tomado decisiones específicas con respecto al segmento en que empezamos una arquitectura. Para Alder Lake y Raptor Lake hicimos Sobremesa y para Tiger Lake hicimos portátiles. Decidimos qué productos vamos a tomar como objetivo primero, pero lo que me gustaría dejar claro con lo que hemos hecho en Meteor Lake, nuestra intención es escalarlo de arriba a bajo en todos los segmentos, desde sobremesa hasta portátiles. En algún momento sacaremos un nuevo nombre de producto, pero anunciaremos eso más adelante.
GEEKNETIC: Y mi última pregunta, ¿Qué te gustaría destacar, con respecto a lo que supone Meteor Lake, si tuvieras que resumirlo en una frase?
Tim: Realmente pienso que Meteor Lake representa un punto de inflexión en el diseño de SoCs para el futuro. Hay unos pocos momentos en el tiempo donde se hace un cambio fundamental en la industria y en la forma en que se desarrollan productos. Y diría que Meteor Lake representa uno de esos pocos momentos en el tiempo. El tiempo será dividido PCs antes de Meteor Lake y PCs después de Meteor Lake.
GEEKNETIC: Tengo que decir que, en muchas ocasiones, cuando estás en mi posición como periodista, resulta que cada generación que se lanza es un punto de inflexión.
Tim: Entiendo, pero te pediría que lo probaras. Ya hemos indicado lo que prometemos con esto, ahora es tu trabajo juzgarnos sobre ello. Desagregación, empaquetado avanzado Foveros 3D, primer PC con IA, E-Cores de bajo consumo, 2 veces el rendimiento gráfico, un 40 a 50% menos de consumo en el SoC. Creo que eso lo justifica un poco, este no es simplemente “la siguiente generación de procesador de cliente”.
Conclusiones de la Entrevista
Algo que se ve claro es que a Intel se han quitado un poco los pelos de la lengua. Antes la actitud era mucho más férrea en defender lo indefensable y da la sensación de que se están centrando más en hacer las cosas bien y ser más transparentes. Es un poco la tónica que se respira 2 años después de la llegada de Pat Gelsinger al liderazgo de la empresa.
Pat en algunas de sus declaraciones no duda en reconocer que perdieron en liderazgo en fabricación y que sus competidores en producto también les han sacado ventaja en algunas cosas. No es raro oír hablar a Pat sobre su buena relación con Jensen de NVIDIA o sobre TSMC y cómo están colaborando con muchísimas empresas que antiguamente tan solo eran competidores.
Esto se ve en gran medida reflejado también en la entrevista con Tim, que nos ha dejado unas pocas sorpresas. Por ejemplo, parece ser que hay la posibilidad de que Meteor Lake llegue a sobremesas en algún momento, aunque ahora que se sabe que los próximos serán Raptor Lake-S Refesh, con toda probabilidad no lo veamos hasta 2024.
Otra de las cosas que Tim ha reconocido es que la arquitectura de los E-Cores y los P-Cores en Meteor Lake no es muy distinta a la de los E-Cores y P-Cores de Raptor Lake, aunque bajo el proceso Intel 4, en el caso del bloque de cómputo, el rendimiento y eficiencia deberían ser considerablemente superiores.

Tim en general parece muy seguro de su producto, durante nuestro encuentro en San José se le notaba ese brillo en los ojos y una pequeña sonrisa de cuando tienes algo realmente bueno entre manos, pero no puede desvelarnos cuánto de bueno es hasta que lleguen los primeros productos. Constantemente me animaba a que lo probemos, que le pasemos todos los test habidos y por haber para verlo por nosotros mismos. Así lo haremos en GEEKNETIC tan pronto tengamos el primer portátil basado en Meteor Lake en nuestro laboratorio de pruebas, y dedicaremos un extenso artículo a ello llegado el momento, tal y como hacemos con todas las generaciones de Intel y de AMD.
Adicionalmente Tim se ha esmerado en enfatizar la importancia de la desagregación con Foveros 3D, hasta el punto de decirnos que es el mayor punto de inflexión en la creación de procesadores de los últimos 40 años.
Ahora te toca a ti, ¿crees que Meteor Lake realmente puede suponer un cambio tan grande? ¿Si el rendimiento y la autonomía realmente demuestran ser tanto como prometen procurarás que tu próximo portátil tenga un procesador basado en Meteor Lake? ¿Qué opinas de que ahora puedan desagregar partes de la CPU y fabricarlas en distintas fábricas para ensamblarlas de nuevo en un único chip?
Fin del Artículo. ¡Cuéntanos algo en los Comentarios!








