


Las PPUs prometen 100 veces más rendimiento en cualquier CPU
por Mikel Aguirre Actualizado: 24/12/2024La PPU, la unidad de procesamiento en paralelo
Una PPU, en ingles Parallel Processing Unit, es un elemento nuevo destinado a complementar a la CPU en un mismo dispositivo o equipo informático. Su finalidad es interactuar con la CPU para otorgarle un procesamiento mucho más paralelo. Esto en función de la implementación puede hacer (según sus creadores) que la CPU rinda hasta 100 veces más rápida, o dicho de otra forma que complete las tareas 100 veces más rápido en determinadas circunstancias.
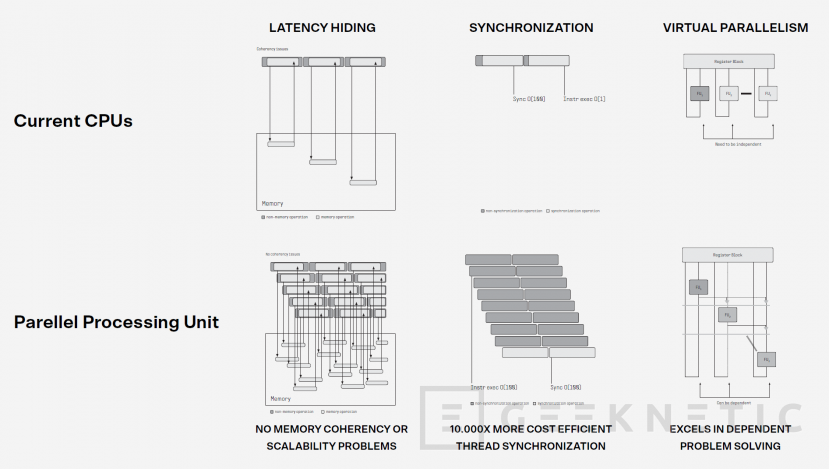
Las PPUs destacan por su técnica de procesamiento paralelo, tarea en la cual es tremendamente eficiente, ya que genera subhilos simultáneos que se sincronizan de forma eficiente para dividir tareas en tareas más pequeñas y así aumentar el rendimiento, de una forma muy distinta a cómo es una CPU convencional de varios núcleos.
Procesamiento Secuencial en CPUs Actuales
La informática tradicional, pese a disponer muchos núcleos en las CPUs, está principalmente pensada para que el procesamiento se produzca de forma secuencial. Tú puedes asignar un hilo a un núcleo y otro hilo a otro núcleo, sin embargo, cada hilo de procesamiento se ejecutará en su núcleo correspondiente de forma secuencial.
Existen casos donde puede dividirse una misma tarea en varios hilos y por ende en varios núcleos, pero son pocos los casos donde realmente se aprovecha. Si la tarea tiene dependencias o requiere de sincronización, la CPU requiere de muchísimos ciclos para procesar dicha sincronización entre núcleos, desperdiciando grandes cantidades de potencia en el proceso.
Está bien poder tener núcleos independientes que puedan procesar cada hilo de forma independiente. Cada hilo de procesamiento se ejecuta de forma secuencial en un núcleo. Sin embargo, existen multitud de operaciones en un hilo que podrían ejecutarse de forma mucho más eficiente y rápida si pudieran dividirse en subhilos. El problema es que hacerlo con las CPUs convencionales resulta muy poco eficiente y por esto los desarrolladores acaban ejecutándolo en el mismo hilo de forma secuencial. Las tareas en las que pasa esto son infinitas, pero estos serían algunos ejemplos: la ordenación de datos, cálculos matemáticos múltiples, lectura de secuencias de datos, etc.
Los compiladores tradicionales ya tienen en cuenta esto y al compilar los programas para su uso en con los sistemas operativos de hoy en día no contemplan la división de estas partes de los hilos entre distintos núcleos, y los dejan en el mismo núcleo donde se está ejecutando, para que la ejecución sea secuencial.
La mayoría del software que se usa hoy en día tiene multitud de operaciones que podrían ejecutarse en subhilos paralelos de forma tremendamente más eficiente, pero por la forma en que están hechas las CPUs no es posible darle solución. Esto es así tanto si hablamos de software de servidor, de software convencional para ordenadores personales, del software de tu móvil y smartwatch, incluso en maquinaria industrial, en los sistemas que gestionan los vehículos, o cualquier otro dispositivo tenga el propósito que tenga.
Lo que se hace cuando tenemos muchos núcleos, en entornos de servidor o de HPC, es desarrollar el software de forma que haga la división en hilos muy evidente. Por ejemplo, un servidor web dispara un hilo para cada petición que obtiene de un navegador y cada hilo se reparte al núcleo que tenga más disponibilidad, sin embargo, si el hilo de una petición concreta requiere de procesamiento de unas tareas concretas, como por ejemplo ordenar un array, esta tarea no se divide y se ejecuta de forma secuencial en el núcleo asignado al hilo.
Curiosamente uno de los puntos donde la CPU produce más cuellos de botella por la falta de procesamiento paralelo es en los juegos, tanto si es una consola, un PC o un móvil, la CPU tiene gran parte de la culpa.
Tener más núcleos no soluciona el problema. Lo único que puede solucionarlo es aumentar las Instrucciones por Ciclo (IPC) o aumentar la frecuencia, y ambas cosas son tremendamente difíciles de conseguir.
La solución que proponen las PPUs
Las PPUs son el antagonista de la CPU en el sentido en que precisamente donde son especialmente eficientes es en la división de tareas de un hilo en distintos subhilos que se procesan en distintos núcleos de la propia PPU.
Estos subhilos son independientes, pero al mismo tienen un sistema de sincronización que da coherencia a las operaciones. Cada subhilo es capaz de acceder a la caché de forma independiente, pero también cada subhilo es capaz de interactuar con otros subhilos de forma que por ejemplo el resultado de dos subhilos pueden ser los operandos para otros subhilos. La sincronización entre subhilos se produce por oleadas según los hilos se van ejecutando.
Gracias a estas técnicas, las PPUs pueden ejecutar en paralelo en todos sus núcleos con gran eficiencia y rendimiento aquellas tareas divisibles que en una CPU se quedarían en un único núcleo ejecutándose de forma secuencial. Esto hace que la velocidad de ejecución de una PPU sea tremendamente más rápida para estas tareas que realmente son divisibles.
No obstante, las PPUs no son perfectas, tan solo son buenas en procesamiento paralelo, para todo lo demás las CPUs siguen siendo mejores.
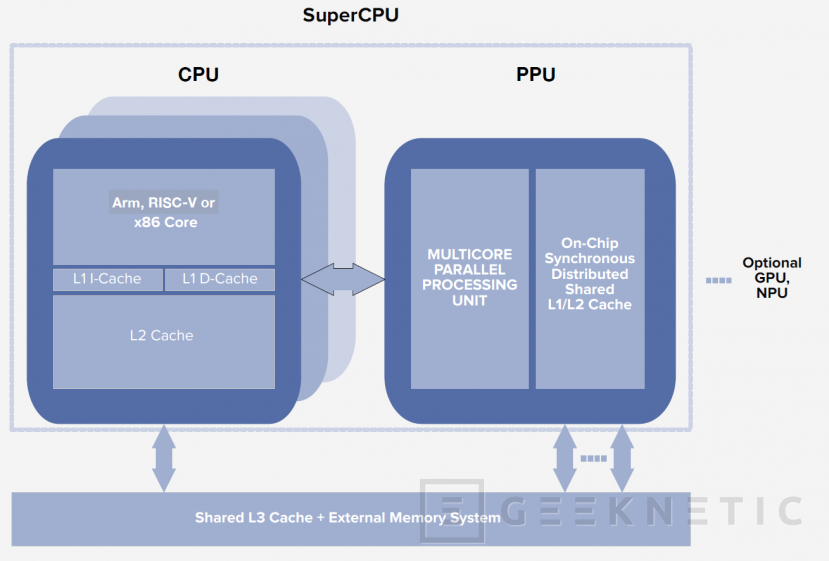
Por tanto, la solución ideal es crear procesadores híbridos que combinen núcleos de CPU con los núcleos de PPU.
Integración de CPUs y PPUs
Podemos plantear que un PC tenga una CPU por un lado y una PPU por otro como ocurre con las tarjetas gráficas y otros elementos. El problema es que la PPU viene a intervenir en cosas que ya de por sí se procesan en la CPU y con datos que existen en su caché. Transmitir los datos de un bloque de silicio separado a otro bloque de silicio sería ineficiente y contraproducente.
Hoy en día muchos tipos de chips son chiplets, conjuntos de baldosas donde por un lado están los núcleos de CPU, por otro los gráficos integrados, por otro el controlador de memoria, etc. Podríamos pensar que la PPU puede ser una baldosa de este chiplet. El problema, sigue siendo el mismo, la PPU tiene que procesar cosas que son de la CPU, no podemos depender del ancho de banda y la latencia de las conexiones entre baldosas.
La solución más acertada es integrar la PPU en la misma baldosa que la CPU, de forma que la CPU y la PPU se comuniquen estrechamente y trabajen al unísono con acceso a la misma caché y memoria.
Además, las CPUs ya tienen su cola de instrucciones propia con su predicción de instrucciones, sería ineficiente crear una cola de instrucciones separada para la PPU. Aprovechando la cola de instrucciones, con una breve modificación se puede hacer que la CPU sea capaz de identificar instrucciones que sean de la PPU y cuando esto ocurra transferir el procesamiento de dichas instrucciones a la PPU. Cuando el procesamiento paralelo se ha completado en la PPU la parte secuencial del hilo de ejecución vuelve a ejecutarse en la CPU.
Podemos decir que una PPU es un acelerador de CPU especializado en ejecución paralela. Al final la CPU sigue siendo quien gobierna el sistema y la PPU con sus propios núcleos pasa a ser un componente más de la misma, junto a los núcleos de CPU convencionales, la caché, etc.
En el ejemplo del servidor web del apartado anterior, en un sistema híbrido CPU+PPU, el servidor web recibe una petición, asigna el hilo al núcleo de CPU correspondiente. Cuando el procesamiento secuencial del hilo en el núcleo llega a un punto donde puede aprovecharse el paralelismo que da la PPU, como por ejemplo la ordenación de un array, la CPU asigna la tarea a la PPU, la PPU reparte el trabajo de ordenación entre distintos subhilos que se ejecutan en los múltiples núcleos de la PPU. Así la PPU consigue ordenar el array de forma mucho más rápida y eficiente, y una vez ha acabado traslada el resultado de vuelta al núcleo de CPU para que continúe el procesamiento secuencial.
¿Con qué tipos de CPU e instrucciones son compatibles las PPU?
Las PPUs son compatibles con todo, pueden crearse PPUs que se integren con núcleos de CPU ARM, núcleos de CPU RISC-V, núcleos de CPU x86 y x64 y prácticamente todo lo que nos podamos imaginar.
Al final la PPU será una parte de la CPU anexa a los núcleos, y puede implementarse en todo lo que tenga una CPU.
Los sistemas operativos tienen que adaptarse para esto, sobre todo la parte de compilación y kernel. Lo mismo con los compiladores que no dependen del sistema operativo. La idea es que el desarrollador de aplicaciones no se vea afectado y sea el compilador y el sistema operativo los que identifiquen cuando un fragmento de código se ha de ejecutar en la PPU y cuando no. De esta forma la transición a sistemas de CPU+PPU sería mucho más sencilla.
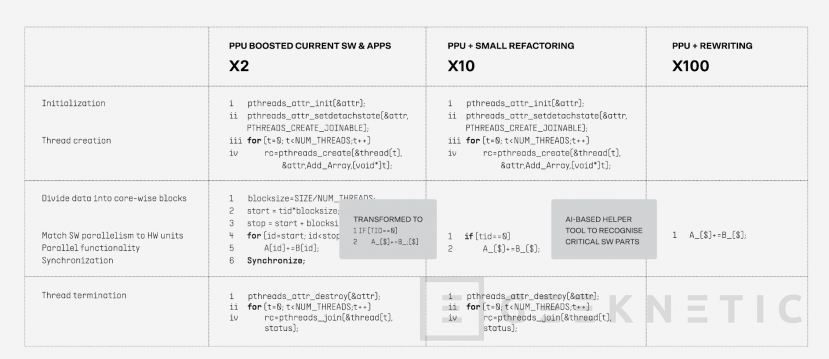
Se puede hacer que sea retrocompatible también, toda aplicación ya compilada debería poder funcionar en un híbrido de CPU+PPU, al fin y al cabo la CPU no la pierdes y puede ejecutar todo lo anterior igual, es solo que no se aprovecharía la PPU.
FLOW Comuting, La empresa detrás de las PPUs
Durante el pasado mes de septiembre en el marco de la feria IFA Berlín, tuve el placer de conocer a Timo Valtonen, el CEO de FLOW Computing. FLOW es una empresa finlandesa de nueva creación y existe específicamente para hacer llegar las PPUs al mundo.
El artífice de todo esto es Dr. Martti Forsell, cofundador de FLOW, que lleva estudiando el procesamiento paralelo desde los años 90 como investigador de la Universidad de Helsinki y del centro de investigaciones finlandesas VTT. Ha trasladado todo su conocimiento y patentes registradas desde VTT a la creación de esta nueva empresa.
Así FLOW nace con numerosas patentes aprobadas y otras pendientes de aprobación en relación al procesamiento paralelo y las PPUs. Esto les permitirá comercializar y llevar al mundo las PPUs para que con suerte todos nos beneficiemos en el futuro cercano.

Modelo de negocio de FLOW Computing
FLOW Computing no fabricará PPUs ni CPUs. Su modelo de negocio es licenciar la tecnología a otras empresas de semiconductores. El modelo de negocio es muy similar al de ARM con sus CPUs Cortex y sus GPUs Inmortalis y Mali. Así una marca que se dedique a hacer CPUs como puede ser Intel, AMD, Qualcomm o cualquiera que nos imaginemos, vendría a comprar la licencia de FLOW y pasaría a implementarla de forma adyacente a los núcleos de CPU tradicionales.
Si esto es así, y los sistemas operativos y compiladores hacen lo propio para soportarlo, podremos ver CPUs comerciales combinando núcleos de CPU convencionales con PPUs en en el futuro cercano.
Funcionamiento de las PPUs de FLOW
Lamentablemente no he podido profundizar tanto como me hubiera gustado en el funcionamiento interno de las PPUs. La compañía todavía no está dispuesta a desvelar los detalles en profundidad porque quieren proteger sus patentes, las cuales aun hay algunas en proceso de aprobación, y su propiedad intelectual.
No obstante, durante mis conversaciones con el Dr. Martti Forsell y Timo Valtonen he obtenido algunas pinceladas.
La clave de todo parece estar la sincronización de los subhilos en oleadas. Cuando una tarea ha sido dividida en subhilos dentro de una PPU, cada núcleo de la PPU procesa su subhilo y tras acaba, envía una señal de sincronización. Dicha señal de sincronización se propaga desde los núcleos hasta la caché de forma que tan pronto se han recibido todas las señales de sincronización pueden volver a lanzarse subhilos para continuar con la tarea.
Lo que esto permite al final es que la sincronización ocurra como parte integral del proceso. Esto permite que multitud de tareas, generalmente indivisibles en una CPU, sean divisibles en una PPU, con el rendimiento que ello otorga.
Según FLOW, seguirá siendo la CPU quien gobierne todo, y tras integrar la PPU, lo único que se necesita es que la CPU reconozca las instrucciones que deben trasladarse a la PPU y que se la propia CPU quien traslade el trabajo a la PPU cuando esto ocurra.

Conjeturas sobre la arquitectura de las PPUs de FLOW
Ya que me he topado con la negativa de FLOW a compartir detalles de la arquitectura de sus PPUs, no me ha quedado más remedio que indagar en los estudios que se han hecho en relación al paralelismo en las últimas dos décadas. Con la información que he obtenido, en muchos casos con trabajos publicados por el mismo Martti Forsell, puedo hacer una serie de conjeturas sobre cómo puede que esté formada la PPU.
Por un lado, cada núcleo tiene todo lo necesario para realizar operaciones, unidades aritméticas, coma flotante y por supuesto la lectura y guardado de registros. Es probable que cada núcleo tenga algo de caché propia también.
Los núcleos de la PPU estarían comunicados entre sí por una red compuesta por DAGs (que son conjuntos de nodos unidireccionales). Cuando un núcleo de la PPU finaliza una tarea y envía un paquete de datos con el resultado, a éste le sigue una señal de sincronización. Tanto el paquete como la señal de sincronización se propagan a través de los DAGs por toda la red. Cada DAG debe esperar a recibir la señal de sincronización desde todos sus extremos de entrada. Una vez ha recibida la señal en todos los extremos, se propaga la señal de sincronización por todos sus extremos salientes.
Si el núcleo de destino a continuar con la tarea recibe paquetes y señales de sincronización en todos sus extremos entrantes, puede iniciar la operación. Esto permite que unos núcleos usen como operandos el resultado obtenido de otros núcleos, de forma prácticamente inmediata. Así funcionaría la llamada sincronización en oleadas que parece ser la clave de su funcionamiento.
Así, cada núcleo y de la PPU y su memoria también estarían comunicados por 2 DAGs uno en una dirección y otro en otra, para facilitar las operaciones de escritura y lectura.
Las primeras CPUs con PPUs de FLOW
El 17 de Octubre de 2024 FLOW desveló que iniciaban una colaboración con RISC-V de forma que esta arquitectura de instrucciones sea la primera en añadir compatibilidad con sus PPUs. RISC-V es un conjunto de instrucciones libre y gratuito. Cualquier empresa de semiconductores puede hacer una CPU para instrucciones RISC-V libremente sin necesidad de pagar licencia alguna por el uso de las instrucciones.
Por el momento FLOW tan solo ha demostrado sus PPUs a través de FPGAs (chips programables que simulan otros chips y que se usa ampliamente en semiconductores). Al programar la FPGA para simular una PPU suya, obtienen las mejoras de rendimiento en paralelización de subhilos que nos prometen. Pero demostrarlo con un FPGA no es lo mismo que verlo en un dispositivo real.
FLOW todavía tiene que demostrar el potencial de las PPUs en un producto final y las grandes empresas de semiconductores no se van a tirar a la piscina sin que el concepto esté sobradamente demostrado. Es por esto por lo que tiene sentido que RISC-V sea el primer conjunto de instrucciones en soportarlo. Al ser instrucciones libres y abiertas, existen numerosas Startups y empresas de nueva creación que están desarrollado sus chips en base a instrucciones RISC-V. No tardaremos en ver alguna de dichas empresas alrededor de RISC-V integrando las PPUs de FLOW.
No tenemos constancia de que haya alguna de las grandes empresas de semiconductores trabajando con FLOW, y si lo estuviera, seguramente no podrían desvelárnoslo de momento. No obstante, teniendo en cuenta los ciclos de desarrollo de CPU, los cambios que tienen que hacerse al software y los sistemas operativos, con toda probabilidad tendremos que esperar al menos 5 años para ver algo que el consumidor pueda disfrutar. 2 años hasta que se vea algo que realmente demuestre en un entorno real el potencial y cautive a las grandes marcas de semiconductores y 3 años más porque suelen ser lo mínimo que duran los ciclos de desarrollo de CPUs.
¿Qué suponen las PPUs de FLOW para el consumidor?
Lo ideal es que las PPUs acaben llegando a todo tipo de procesadores, incluyendo las CPUs convencionales de AMD, de Intel y de Qualcomm, de forma que aceleren nuestros PCs, smartphones y todos nuestros dispositivos de forma exponencial. Curiosamente el gaming es una de las cosas que se vería tremendamente beneficiada, aunque prácticamente todo tipo de procesamiento se debería poder beneficiar en gran medida, según FLOW Computing.
Siguiendo el ejemplo del gaming, las CPUs siguen siendo a día de hoy el motivo de los cuellos de botella importantes en PCs para jugar y por mucho que tengas la mejor Tarjeta Gráfica del mundo, la CPU sigue teniendo un impacto importante. Son estos cuellos de botella a los que las PPUs pueden darle solución.
En cualquier caso y por excitante que esto nos parezca, lo lógico en este punto es ser escépticos y poner los pies en la tierra de momento. Multiplicar el rendimiento por 100 suena a fantasía, y aunque lo que dice FLOW sea cierto y esas tareas que ahora son secuenciales dentro del mismo hilo y que una PPU pueda acelerar 100 veces, no significa que esto automáticamente haga que tu PC sea 100 veces más rápido en todo.
En cualquier caso toda mejora por pequeña que sea es importante. Los ingenieros que trabajan en las empresas de semiconductores lloran de alegría cuando ven que han conseguido arañar un 1% más en rendimiento a una arquitectura con una nueva característica. Si FLOW les diera un 10% ya sería todo un logro.
Fin del Artículo. ¡Cuéntanos algo en los Comentarios!








