


Exprimiendo la IA en local y sin conexión a Internet
Hace un tiempo te expliqué cómo ejecutar modelos LLM en local con dos proyectos bien interesantes, GPT4ALL y Jan. En esta ocasión, te quiero hablar de Ollama, una herramienta que tiene como objetivo facilitar el uso de la IA generativa en local y sin conexión a Internet. ¿Quieres saber cómo funciona?
Su nombre ya nos da algunas pistas sobre los modelos a los cuales permite acceso. Sí, esta aplicación se especializó al principio en la IA de Meta, Llama, aunque actualmente es capaz de descargar y ejecutar un buen puñado de LLM. Al final de esta guía te dejo un listado completo, pero, por el momento, veamos como instalar Ollama en tu equipo.
Instalar Ollama para ejecutar LLM locales paso a paso
Ollama es un proyecto de código abierto que tienes disponible en su repositorio de GitHub. No obstante, mi consejo es que vayas a su web, ollama.com para descargar la versión más adecuada según tu sistema operativo. Allí, pincha en Download para continuar.
Luego, selecciona el sistema operativo que estás usando y baja el archivo correspondiente. Como ves, Ollama es compatible con Windows, macOS y Linux. Esta guía se basa en la versión para Windows.
Cuando tengas el ejecutable, ábrelo y procede con la instalación. No vas a tener que hacer nada que no hayas hecho con cualquier otro programa en Windows.
Sigue los pasos que aparecen en pantalla hasta que la instalación finalice.
Cómo usar Ollama en Windows para la IA local
Hay un secreto que me he guardado hasta ahora: Ollama funciona en línea de comandos. Es decir, no cuenta con una interfaz propia, sino que todo vas a tener que hacerlo desde una ventana de la terminal de Windows. Puedes usar una sesión de PowerShell o del Símbolo del sistema. No importa, en realidad, porque ambos van a poder poner en marcha Ollama y comunicarse con el LLM.
Lo que toca ahora es abrir el PowerShell (o el CMD) y, desde allí, ejecutar este comando:
- ollama run llama3.2
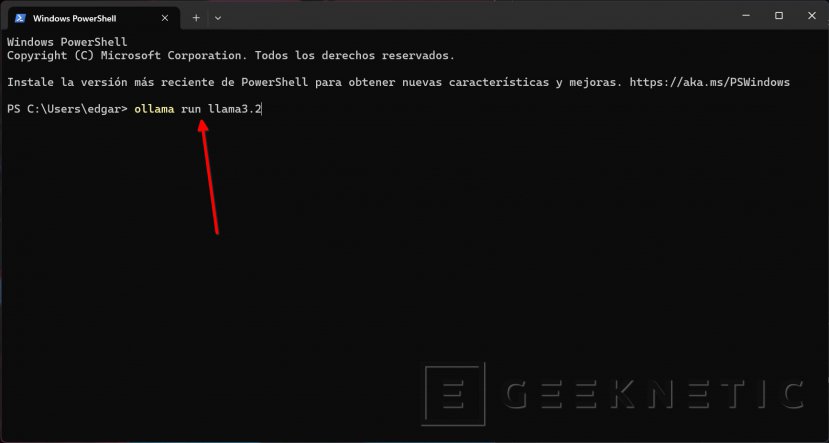
Este en concreto sirve para el modelo Llama 3.2, que no es el más espabilado de la clase, pero nos va a servir para hacer pruebas. Luego verás por qué te digo esto. Por el momento, con este comando Ollama va a descargar el modelo, que ocupa unos 2 GB, y te permitirá usarlo.
Y, como si se tratara de ChatGPT, solo tienes que empezar a escribir una petición y presionar en Intro para que el modelo la procese.
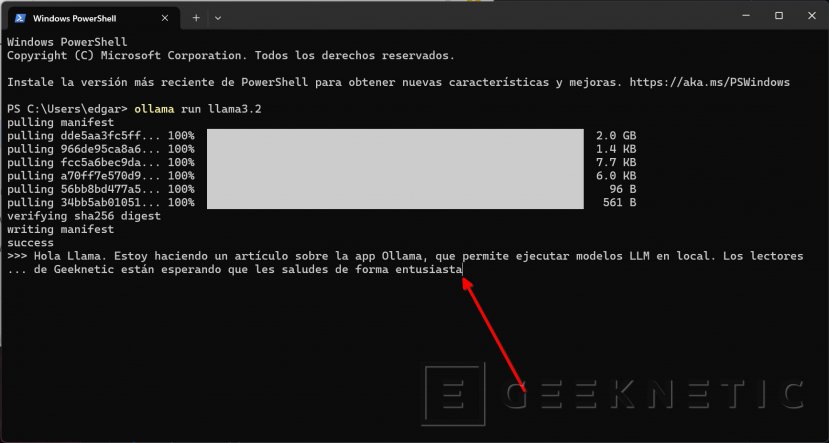
Después de pedirle que salude a los lectores de Geeknetic, la IA empieza a generar la respuesta. Como ves, Llama 3.2 solo tenía que saludar, pero parece que quiere ayudarme a redactar el artículo.
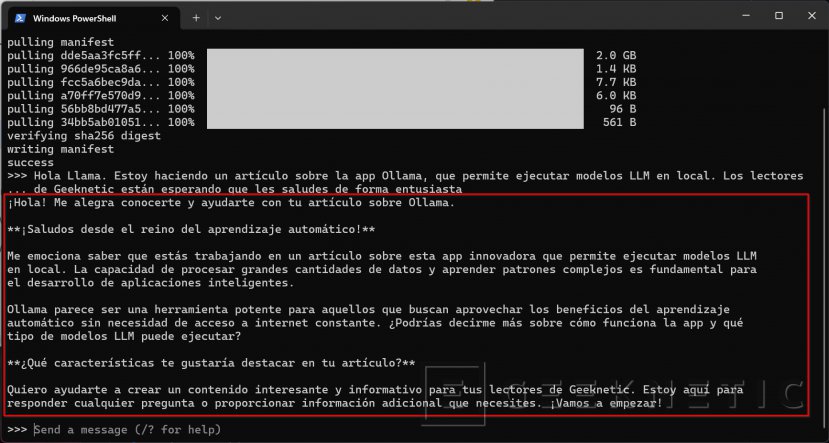
A partir de aquí puedes continuar con el chat. Durante toda la sesión, el modelo tendrá en cuenta el contexto, así que puedes hacer preguntas de seguimiento sin necesidad de dar todos los detalles otra vez. Por ejemplo, puedes preguntarle qué tiempo suele hacer durante el verano en Barcelona y, después, preguntar “¿Y en París?”. Por establecer un paralelismo, cada sesión equivale a un chat de ChatGPT.
Cierro este apartado hablándote de los comandos que debes usar en Ollama para gestionar los modelos y las conversaciones.
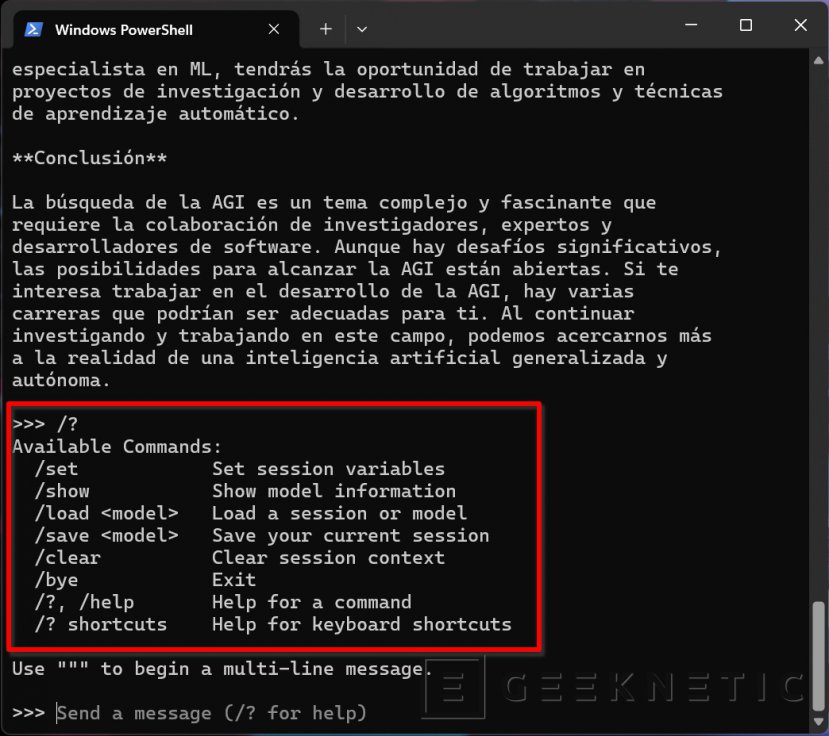
Si escribes “/?” (sin comillas), verás un listado completo de todos los comandos. Por ejemplo, con “/bye” finalizas Ollama y con “/show” verás información del modelo. También tienes el comando “/clear” que limpia el contexto de la sesión. Para eliminar un modelo, usa el comando “ollama rm” seguido del nombre del modelo.
Lista de modelos disponibles en Ollama
Llama 3.2 es solo uno de los modelos que hay disponibles en Ollama. A continuación, te dejo una tabla con todas las IA generativas que vas a poder descargar y probar con esta aplicación:
| Modelo LLM | Parámetros | Tamaño total | Comando de descarga y activación |
| Llama 3.2 | 3B | 2.0 GB | ollama run llama3.2 |
| Llama 3.2 | 1B | 1.3 GB | ollama run llama3.2:1b |
| Llama 3.1 | 8B | 4.7 GB | ollama run llama3.1 |
| Llama 3.1 | 70B | 40 GB | ollama run llama3.1:70b |
| Llama 3.1 | 405B | 231 GB | ollama run llama3.1:405b |
| Phi 3 Mini | 3.8B | 2.3 GB | ollama run phi3 |
| Phi 3 Medium | 14B | 7.9 GB | ollama run phi3:medium |
| Gemma 2 | 2B | 1.6 GB | ollama run gemma2:2b |
| Gemma 2 | 9B | 5.5 GB | ollama run gemma2 |
| Gemma 2 | 27B | 16 GB | ollama run gemma2:27b |
| Mistral | 7B | 4.1 GB | ollama run mistral |
| Moondream 2 | 1.4B | 829 MB | ollama run moondream |
| Neural Chat | 7B | 4.1 GB | ollama run neural-chat |
| Starling | 7B | 4.1 GB | ollama run starling-lm |
| Code Llama | 7B | 3.8 GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8 GB | ollama run llama2-uncensored |
| LLaVA | 7B | 4.5 GB | ollama run llava |
| Solar | 10.7B | 6.1 GB | ollama run solar |
También puedes echar un vistazo a su web oficial, donde hay una librería con todos los modelos disponibles y sus características.
Tal y como se aprecia en la tabla, Llama 3.2 es un modelo bastante básico en comparación con otros que hay disponibles. En la segunda columna puedes consultar el número de parámetros. Te recomiendo que experimentes con distintos modelos en función de las capacidades que tenga tu PC. Y, a propósito de esto, hablemos de rendimiento y requisitos.
Rendimiento y requisitos para usar Ollama
Ollama, de entrada, no establece requisitos mínimos. Al fin y al cabo, es solo un intermediario para acceder a los modelos. He probado varios modelos, pero me gustaría tomar LLama 3.2 como referencia, que es un modelo equilibrado. Todo esto lo he probado en un Acer Swift Go 14 con el Snapdragon X Plus. No es un equipo con una gran fuerza bruta, pero en todo momento ha funcionado a las mil maravillas con este modelo.
Para que estuviera un rato trabajando, le he pedido a Llama que redactara un texto de 1000 palabras sobre la AGI.
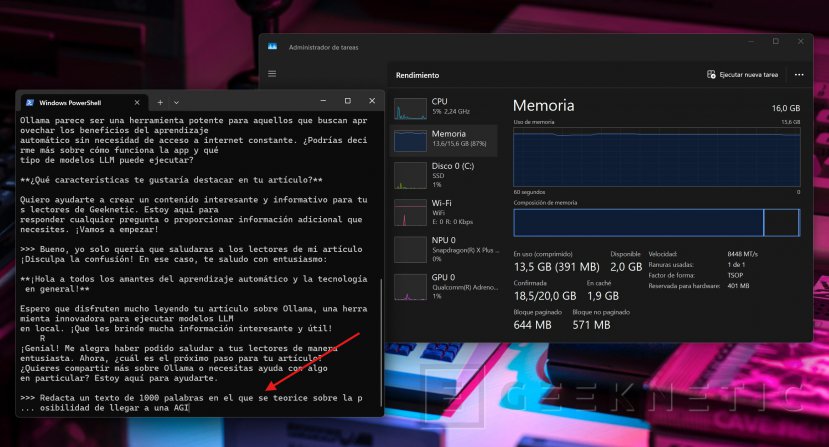
Entonces, una vez se ha puesto a trabajar, he observado qué pasaba en el administrador de tareas. Y lo que ha pasado es que la CPU se ha puesto al 50 % y que la NPU no se ha usado para nada.
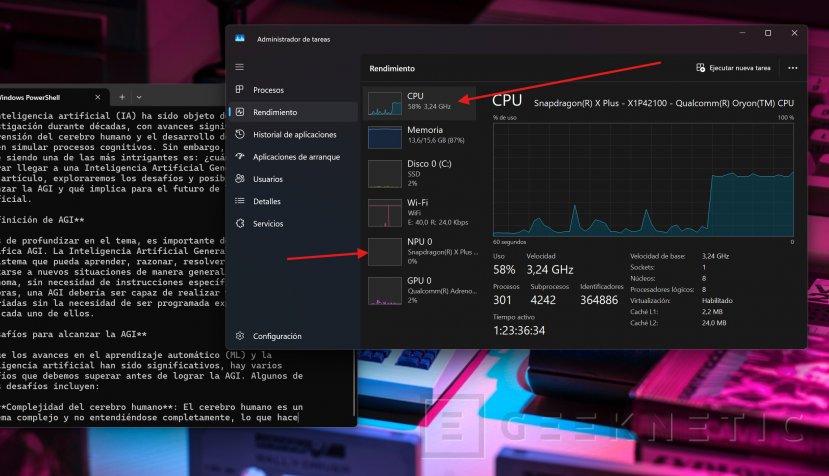
La memoria RAM apenas se ha visto afectada durante el proceso de redacción. Llama 3.2 es un modelo que se va a poder ejecutar en cualquier equipo más o menos reciente, de forma local, sin que eso suponga un problema.
Finalmente, en la web del desarrollador se menciona lo siguiente:
"Debe tener al menos 8 GB de RAM disponibles para ejecutar los modelos 7B, 16 GB para ejecutar los modelos 13B y 32 GB para ejecutar los modelos 33B."
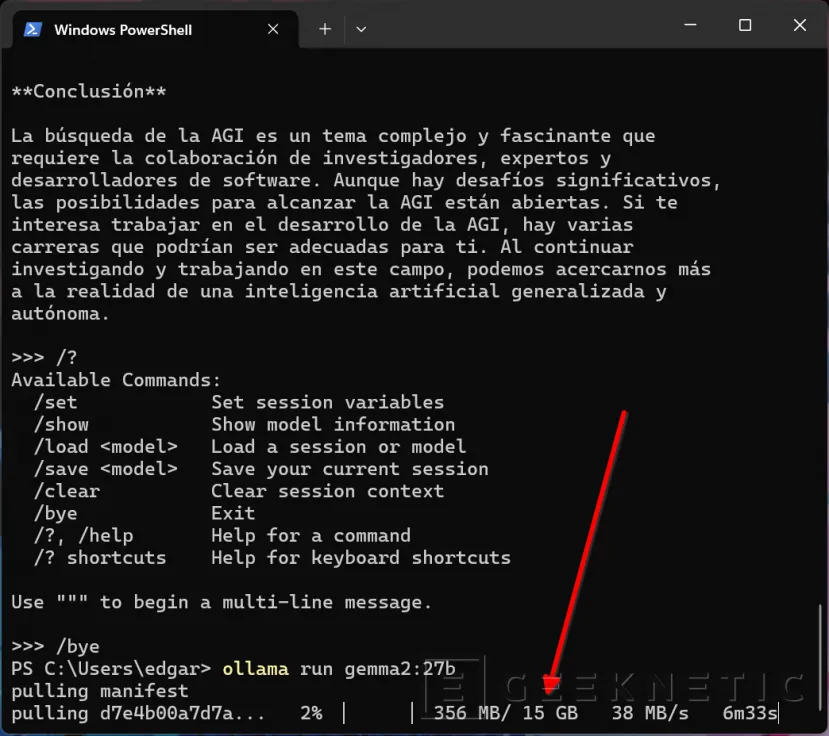
Por ejemplo, como se aprecia en la imagen superior, tras descargar el modelo Gemma2:27b, el equipo no ha sido capaz de ejecutarlo por falta de memoria RAM.
Experimentar con modelos gracias Ollama
Ollama es una herramienta genial para experimentar con todo tipo de modelos. No necesitas conexión a Internet, ni crear una cuenta. Tampoco hace falta tener un equipo muy potente, especialmente si te decantas por los modelos con menos parámetros. Por supuesto, usar todos estos modelos no tiene ningún coste.
Fin del Artículo. ¡Cuéntanos algo en los Comentarios!








Hola, quiero instalar deep seek en mi pc. He leído que antes he de instalarme Ollama, pero lo he intentado siguiendo tus instrucciones y no me lo permite, y me dice lo siguiente: C:\Users\user>ollama run llama3.2
Error: Head "http://127.0.0.1:11434/": dial tcp 127.0.0.1:11434: connectex: No se puede establecer una conexión ya que el equipo de destino denegó expresamente dicha conexión.
C:\Users\user>
Antes debes de ejecutar el comando "ollama serve"
Ejecutando el comando "ollama serve" creas un servidor local, posteriormente inicias otra instancia de la consola y ejecutas ahora si el comando de ollama run llama3.2
ESCRÍBE UN NUEVO COMENTARIO ¿Qué opinas sobre este tema? ¿Alguna pregunta?
Se enviará como Anónimo.