


NVIDIA RTX 30: ¿Cómo consigue la arquitectura Ampere duplicar el rendimiento de las RTX 20?
por Antonio Delgado Actualizado: 18/05/2021 6Introducción a la arquitectura Ampere en las RTX 30
Recientemente, el día 1 de este mes de septiembre de 2020, NVIDIA anunció oficialmente el lanzamiento de sus nuevas series de tarjetas gráficas NVIDIA GeForce RTX 30 basadas en su nueva arquitectura gráfica Ampere, a la que ya dimos un repaso completo en esta editorial.
Los modelos anunciados fueron las NVIDIA GeForce RTX 3070, GeForce RTX 3080 y la GeForce RTX 3090, unas GPU que han dado uno de los saltos generacionales más altos, consiguiendo prácticamente doblar el rendimiento de la generación anterior con un rendimiento por vatio un 1,9x superior a las RTX 20 con arquitectura Turing.
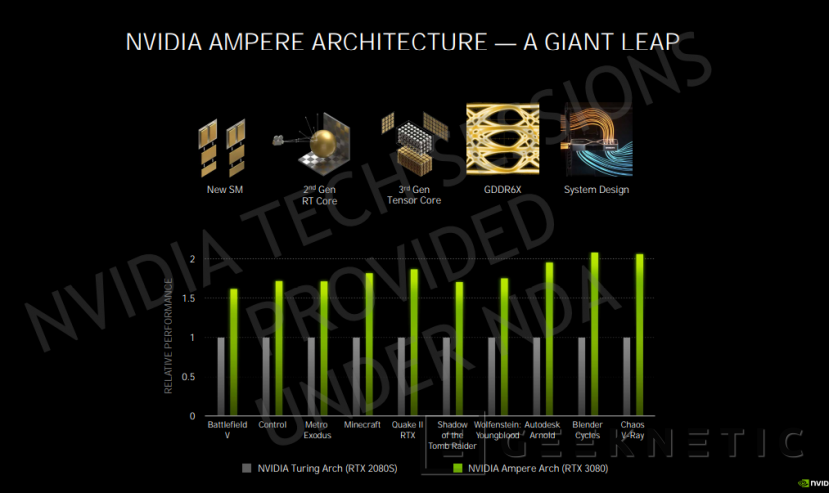
Hablamos de que, según los datos de NVIDIA, la RTX 3070, con un precio de 512 Euros, ofrecerá un rendimiento ligeramente superior que el de la RTX 2080 Ti, la reina de la pasada generación. Mientras que una RTX 3080 ofrecerá el mismo rendimiento que dos RTX 2080 con un precio menor (719 euros) que una sola de estas tarjetas en su lanzamiento.
| RTX 30 Series (Founders) | RTX 3070 | RTX 3080 | RTX 3090 |
|---|---|---|---|
| Arquitectura | NVIDIA Ampere | NVIDIA Ampere | NVIDIA Ampere |
| Proceso de fabricación | 8 nm (Samsung) | 8 nm (Samsung) | 8 nm (Samsung) |
| Reloj GPU (Boost) | 1.73 GHz | 1.71 GHz | 1.7 GHz |
| VRAM | 8 GB GDDR6 | 10 GB GDDR6X | 24 GB GDDR6X |
| Reloj Memoria | 16 Gbps | 19 Gbps | 19.5 Gbps |
| CUDA Cores | 5888 | 8704 | 10496 |
| Bus | 256-bit | 320-bit | 384-bit |
| Ancho de banda | 512 GBps | 760 GBps | 936 GBps |
| TDP | 220 W | 320 W | 350 W |
| Temperatura Máx | 93ºC | 93ºC | 93ºC |
| Puertos | 1x HDMI 2.1 + 3x DP 1.4a | 1x HDMI 2.1 + 3x DP 1.4a | 1x HDMI 2.1 + 3x DP 1.4a |
| Tamaño | 242 x 112 mm (2 slots) | 285 x 112 mm (2 slots) | 313 x 138 mm (3 slots) |
| Disponibilidad | octubre | 17 septiembre | 24 septiembre |
| Precio | 519 Euros | 719 Euros | 1.549 Euros |
Finalmente, la RTX 3090, toda una demostración de fuerza y poderío tecnológico por parte de NVIDIA, contará con el chip Ampere en su totalidad, con 10496 CUDA Cores a 1,7 GHz acompañados de 24 GB de memoria GDDR6X, su precio será de 1.549 euros y podrá manejar juegos en 8K con HDR gracias a tecnologías como DLSS 8K. Su rendimiento es 1,5 veces más rápido que el de la NVIDIA TITAN RTX, la gráfica más potente de la compañía hasta ahora.
Se suman a estas tarjetas nuevas tecnologías como el sistema de gestión directa de memoria RTX IO para poder acceder al almacenamiento NVMe sin pasar por la CPU, o el sistema de reducción de latencia NVIDIA Reflex o la aceleración mediante Inteligencia Artificial a la hora de hacer streaming a tiempo real con efectos de todo tipo. De todas estas tecnologías implementadas en las RTX 30 hablaremos a lo largo del artículo.
Ahora bien, ¿Cómo ha hecho NVIDIA para duplicar el rendimiento de la pasada generación de golpe? La respuesta la encontramos precisamente en la implementación específica que ha hecho NVIDIA de la arquitectura Ampere en su gama GeForce RTX 30 con, entre otras novedades, la implementación de la segunda generación de RT Cores con soporte para concurrencia y la tercera generación de los Tensor Cores para funciones basadas en IA como DLSS. A lo largo de gran parte de esta editorial desgranaremos todos los secretos de la arquitectura Ampere en esta nueva gama de tarjetas gráficas.

Estructura interna de las GPU Ampere
Empezamos mostrando directamente el esquema interno de una RTX 3080, una de las nuevas gráficas GeForce RTX 30 con la nueva arquitectura Ampere fabricada mediante un proceso de 8 nanómetros de Samsung que le permite integrar más transistores por área.
Si la comparamos con la RTX 2080S, aumenta el número de Sm desde los 48 SMs hasta los 68 SMs para ofrecer más del doble de CUDA Cores, pasando de 3072 a 8702 y consiguiendo una potencia de cálculo de 30 TFLOPS, con procesamiento de 164 Gpixeles/s, 465 Gtexels/s y hasta 760 GB/s de ancho de banda.
Podemos ver la distribución interna en seis GPCs, con 12 SMs para cuatro de ellos y 10 SM para otros dos, para ese total de 64 SMs.

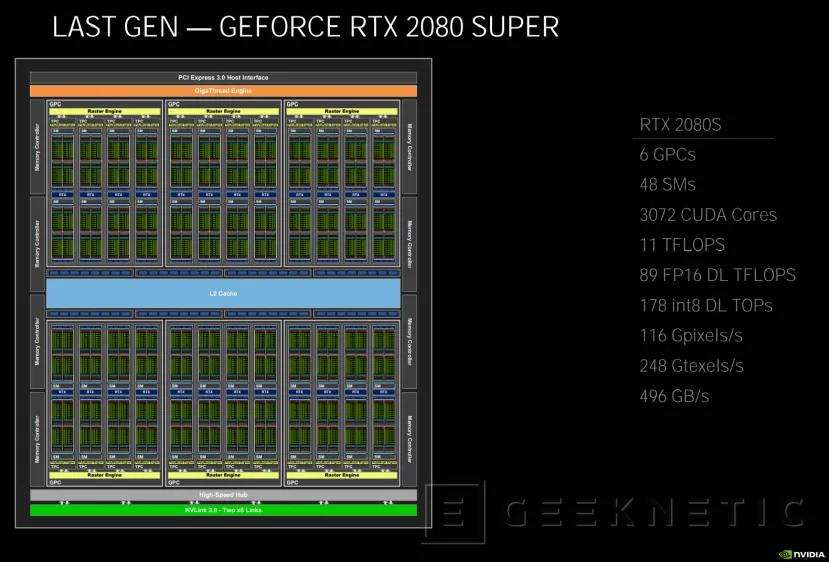
La GPU de una RTX 2080 Super basada en Turing, llegaba con 48 SMs para un total de 3072 CUDA Cores y 11 TFLOPS. Su ancho de banda máximo era de 494 GB/s y era capaz de procesar 116 Gpixels/2 y 248 Gtexels/s.
Cada uno de los SMs de Ampere tiene cambios sustanciales y mejoras respecto de la pasada generación, veamos de qué se tratan.
Nuevo diseño de SMs con doble de unidades FP32
La mayoría de las razones de la duplicación del rendimiento en la nueva arquitectura Ampere las encontramos en la evolución del diseño de los SM de la GPU respecto del integrado en Turing. Ahora, en Ampere, en vez contar con cuatro unidades FP32 y otras cuatro INT 32, tenemos cuatro FP2 y cuatro combinada FP2 + INT32 por cada SM, es decir, el doble de unidades FP32. De esta manera se consigue favorecer la simultaneidad de las operaciones para conseguir evitar cierto cuello de botella que se podía ocasionar en las anteriores gráficas con arquitectura Turing.
Además, se ha duplicado el ancho de banda de la memoria caché L1 al mismo tiempo que se multiplica también por dos el tamaño de la partición de caché, con un tamaño total un 33% superior al de la arquitectura predecesora.

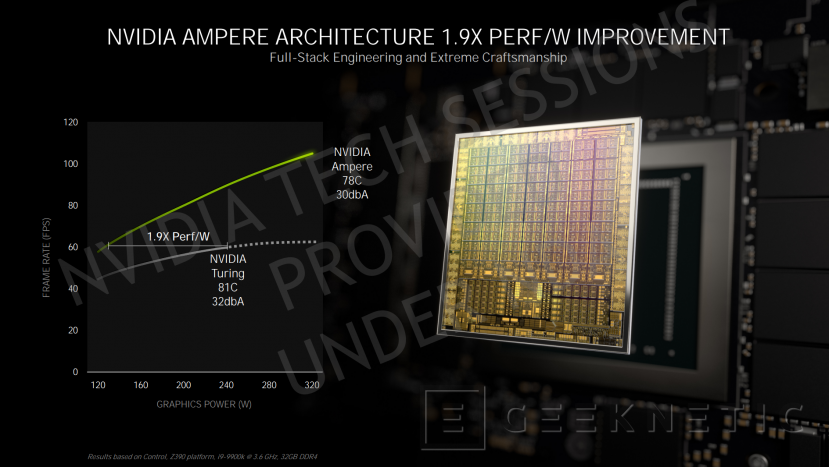
Entrega de energía de doble raíl para aprovechar el 1,9x más de rendimiento por vatio
El rendimiento por vatio ha aumentado hasta 1,9x en Ampere respecto a Turing. Esto supone que el escalado de rendimiento respecto de la potencia es mucho mayor y deriva hacia un nuevo sistema de entrega de energía, que pasa de un único raíl como teníamos en Turing, a dos raíles, uno dedicado al sistema de memoria y otro para los gráficos.
La razón de esta división es la de poder optimizarla entrega de energía en cada momento para conseguir aprovechar ese mayor rendimiento por vatio que ofrece Ampere, de tal forma que se podrán aplicar distintos voltajes y energía a la parte de la gpu y al sistema de memoria, mientras que en Turing la subida o bajada de estos valores era común a ambos.
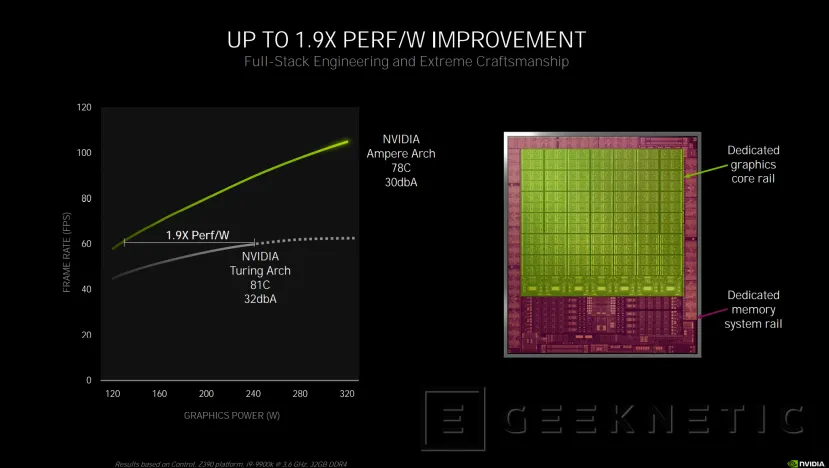
Otra consecuencia de esto es que, probablemente, las RTX 30 permitan unos mayores aumentos de rendimiento al hacer overclock que en la generación anterior. Naturalmente, para ello haría falta una fuente y un equipo capaz.
RT Cores de segunda generación con el doble de rendimiento en cálculo de intersecciones
Donde hay cambios también muy importantes, como ya adelantamos, es en los RT Cores y en los Tensor Cores. Los RT Cores de segunda generación que integra Ampere duplican la capacidad de cálculo de intersecciones triangulares respecto a Turing.
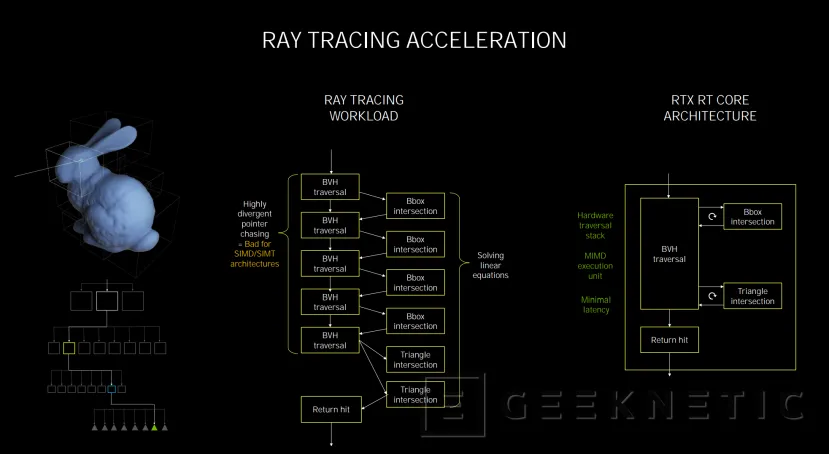
Este cálculo de intersecciones triangulares son las que hacen que las gráficas RTX puedan aumentar su rendimiento a la hora de procesar raytracing. Cada RT Core, como ya ocurría en Turing, se encarga de calcular la intersección de triángulos de rayos y la optimización de las intersecciones dentro de un volumen para centrar los recursos de la GPU en los elementos necesarios para la escena que se está visualizando y no desperdiciar recursos, ya que en una arquitectura GPU convencional sin RT Cores, es necesario calcular cada intersección.
En Ampere se duplica la capacidad de cálculo de estas intersecciones triangulares y, además, se introduce un nuevo elemento como es la aceleración por hardware de efectos de Motion Blur.
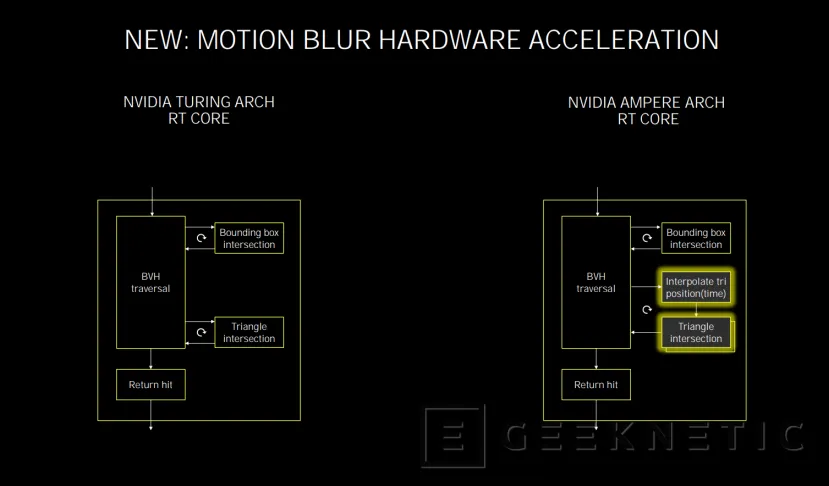
De esta forma, los RT son capaces de acelerar el procesado de efectos de motion blur o desenfoque de movimiento en raytracing, con 8 veces más rendimiento que la generación anterior.

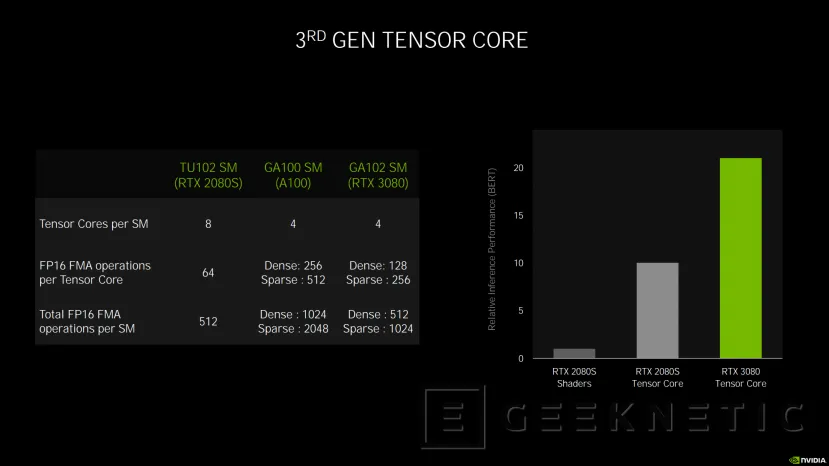
Tensor Core de tercera generación optimizados para operaciones IA con matrices dispersas
Por otro lado, la tercera generación de los Tensor Core consiguen el doble de rendimiento en operaciones matemáticas con matrices dispersas para el cálculo de IA.
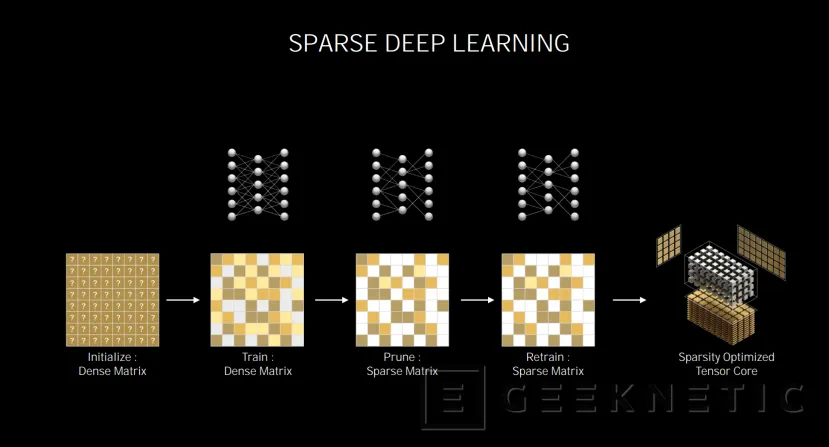
Cada SM de una GPU Ampere como la RTX 3080 (GA102 SM) o la A100 (GA100SM) integra cuatro tensor cores de tercera generación por cada SM, la mitad que los ocho con los que contaban las RTX 2080 Super por ejemplo, con la GPU TU102).
A pesar de esta reducción de Tensor Cores, la tercera generación consigue el doble de operaciones por Tensor Core en matrices densas (128 vs 64) y hasta cuatro veces más en matrices dispersas.
Eso supone que, por cada SM, la RTX 3080 es capaz de calcular 512 operaciones de matrices densas y 1024 de matrices dispersas contra las 512 genéricas de Turing.
GDDR6X, la memoria gráfica más rápida del mundo.
Una de las novedades que se ha introducido en estas NVIDIA RTX 30 con Ampere son las memorias gráficas GDDR6X, una evolución de las GDDR6 que integraba la anterior generación que le permite convertirse en las memorias gráficas más rápidas del mercado.
Este tipo de memoria se integra únicamente en los dos modelos más potentes, la RTX 3080 con 10 GB GDDR6X y la RTX 3090 con 24 GB GDDR6X, ya que la RTX 3070 mantiene 8 GB de memoria GDDR6.
En el caso de la RTX 3080, los 10 GB de memoria GDDR6X funcionan a 19 Gbps con un bus de datos de 320-bits y un ancho de banda de 760 GBps, mientras que la RTX 3090 aumenta su reloj hasta los 19,5 Gbps con un bus de 384 bits para un ancho de banda total de 936 GBps.
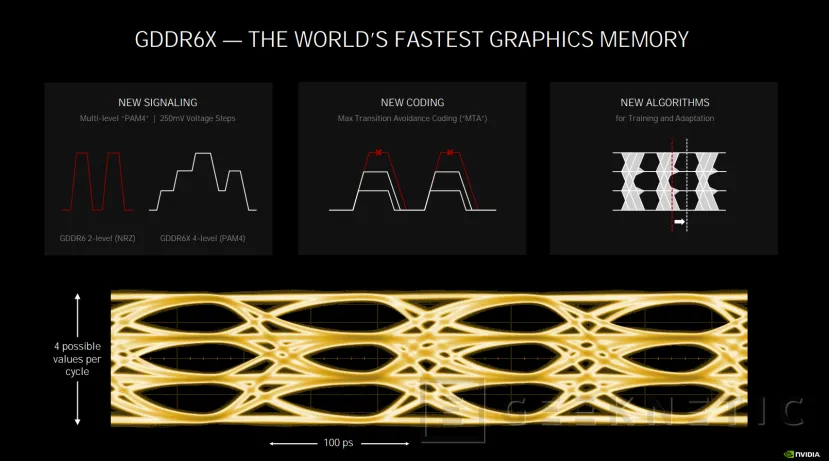
La memoria GDDR6X en Ampere utiliza un nuevo sistema de señalización de cuatro niveles contra los dos niveles de la GDDR6, además de una nueva codificación que permite realizar las transiciones entre los 4 nuevos estados de manera más sencilla y rápida. Además, se incluyen nuevos algoritmos para entrenamiento y adaptación.
La nueva concurrencia de hilos y sus implicaciones en el rendimiento
Una de las novedades que introduce Ampere es la llamada "Concurrencia de Hilos". Cuando se renderiza un fotograma de un juego con raytracing, en una gráfica sin RT Cores se utilizan los Shaders. Esto supone un coste de recursos muy alto que puede hacer que generar ese frame suponga un retardo o latencia de 51 milisegundos.
Con la introducción de Turing y los RT Cores, la parte del cálculo y optimización de operaciones para el Raytracing se realizaba en los RT Cores, haciendo que los tiempos de generación de frames se redujeran a menos de la mitad, en este ejemplo concreto a 20 ms.
La tecnología DLSS 2.0 supuso una mejora importante en cuanto al rendimiento que podían ofrecer las RTX; permitiendo generar, mediante inteligencia artificial y los Tensor Core de las RTX, imágenes de mayor resolución y mayor calidad con un menor coste de cómputo para la gráfica. Sin embargo, en la arquitectura Turing no era posible utilizar los RT Cores y los Tensor Cores de manera simultánea.
Por tanto, aunque se reducían los tiempos de generación del fotograma (en el ejemplo pasamos de 20 ms a 12 ms), el DLSS se aplicaba después de haber calculado el Raytracing.
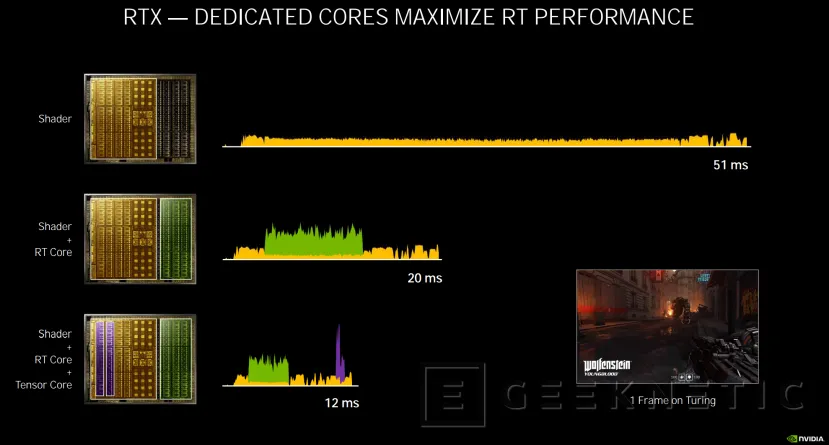
Esto cambia ahora con Ampere, permitiendo el uso de los CUDA Cores para rasterizar, y los RT Cores para el Raytracing funcionando de manera concurrente junto a los Tensor Core para la aplicación de DLSS 2.0 a tiempo real. Cada uno con su propio hardware dedicado para funcionar en paralelo al mismo tiempo.
En la siguiente diapositiva podemos ver como con Turing, 1 frame con Raytracing y DLSS tarda 13 ms en generarse, con Ampere, utilizando el mismo procesado lineal, se reduce a 7,5 ms debido a las mejoras de rendimiento de la arquitectura y el doble datapath.
Sin embargo, si aprovechamos la concurrencia de segunda generación de Ampere que permite utilizar la parte gráfica (amarillo) + los RT Cores para RTX(verde) + Tensor Cores para el DLSS (morado), conseguimos reducir a 6,7 ms la latencia. Aun así, hay que comentar que realmente el DLSS no se está aplicando en ese mismo frame, sino que sería del anterior.
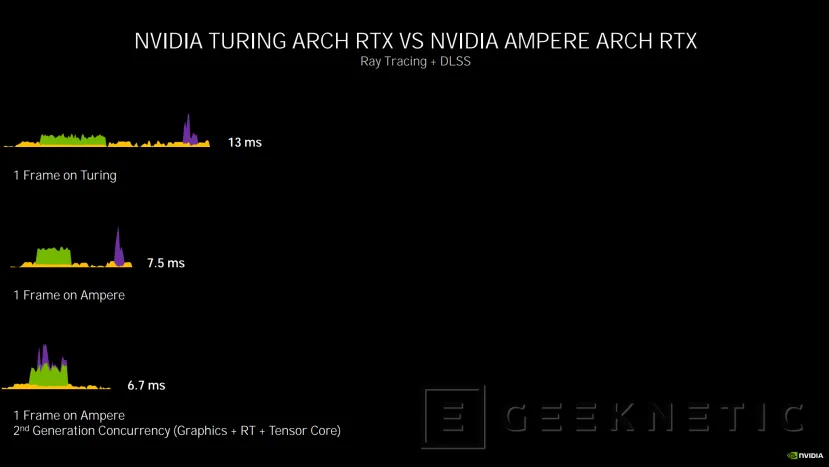
Hemos realizado este gráfico para explicarlo de manera más clara, basándonos en el cálculo de la propia arquitectura Ampere. Si estamos generando varios frames en un juego con ejecución lineal, el primer frame se genera con rasterizado (amarillo) y raytracing con RT Cores (verde) y, posteriormente, se aplica el DLSS (morado). Una vez acaba, se empieza con el segundo, y así sucesivamente.
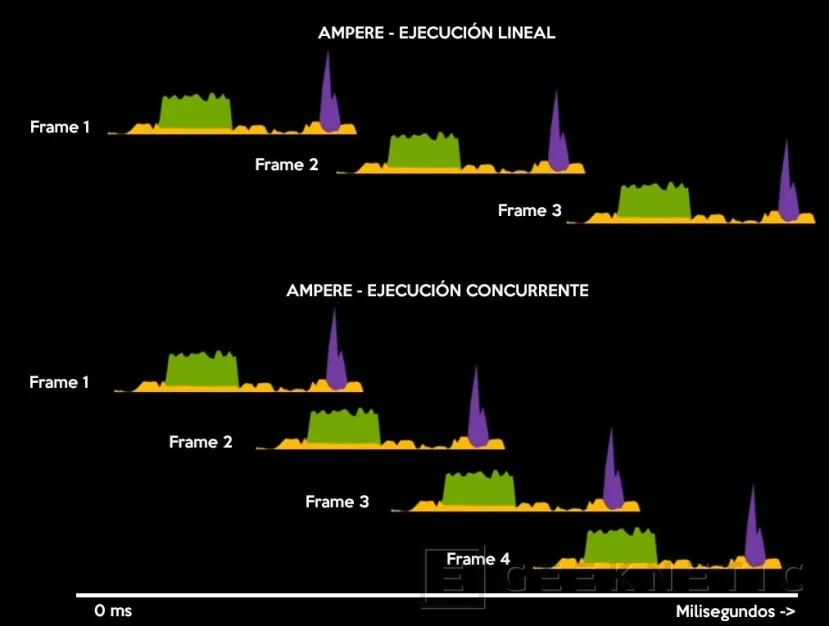
Con ejecución concurrente, cuando el primer frame acaba de generarse y se le aplica el DLSS con los Tensor Cores, a la vez, los RT Cores y los Shaders están ya generando el siguiente frame antes de que finalice la aplicación del DLSS, reduciendo la espera entre frames y, por tanto, aumentando los FPS.
RTX IO, acceso directo al NVMe desde la GPU
Otra de las tecnologías que NVIDIA anunció con las RTX 30 basadas en Ampere (aunque también funcionará en gráficas de la generación anterior RTX 20), es el denominado RTX IO. Este sistema busca evitar ciertos cuellos de botella que pueden aparecer al acceder a los datos del almacenamiento del sistema para ser procesados en la GPU.
RTX IO es al final la implementación en las tarjetas gráficas RTX del nuevo estándar DirectStorage que Microsoft ha añadido a DirextX 12.
El almacenamiento cada vez es más rápido, pasamos de discos duros mecánicos con velocidades de 100 MB/s a SSD SATA que multiplican por cinco esa velocidad, y ahora los SSD NVMe PCIe alcanzan 3.500 MB/s y hasta 7.000 MB/s en las unidades PCIe 4 de nueva generación.
Cada vez es más común ver juegos que ocupan más de 100 GB y la cifra aumenta año tras año y lanzamiento tras lanzamiento de los grandes títulos que van llegando al mercado. Los desarrolladores utilizan sistemas de comprensión sin pérdida para poder procesar tal cantidad de dato, una técnica realizada en la CPU que, si bien no supone un problema en su descompresión a un disco duro lento, a la hora de descomprimirse hacia un SSD, hace que se requieran de múltiples núcleos del procesador y potencia de cálculo.
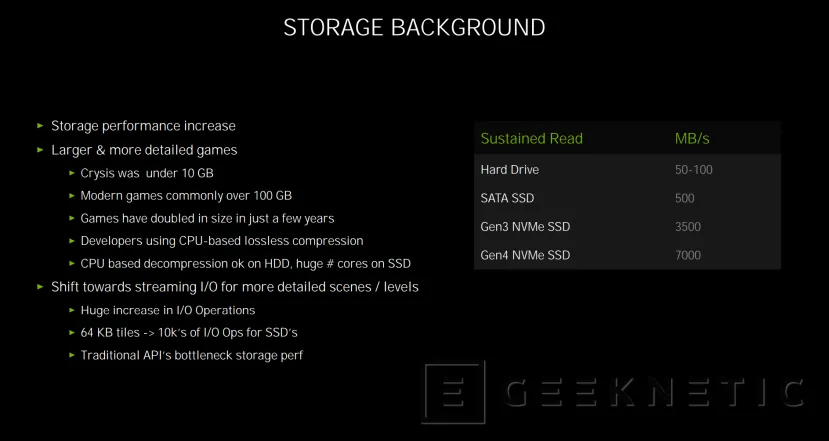
Esos datos, si utilizamos un SSD NVMe PCIE 4.0, van desde el SSD hasta la CPU (pasando por el PCIe) para procesarse en memoria y volver, mediante el bus PCIe Express otra vez, hacia la GPU y su memoria a la hora de generar los fotogramas. En el caso de ser datos comprimidos, se necesita de múltiples hilos de CPU para su procesado.
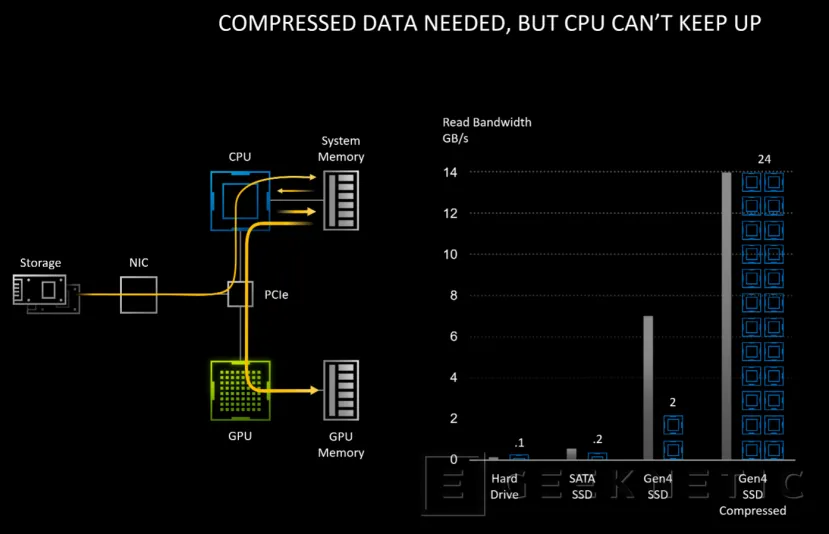
La idea detrás de RTX IO es la de, mediante el uso de la API DirectStorage de Microsoft, hacer que se puedan leer los datos comprimidos desde el SSD NVMe directamente en la GPU y en su memoria gráfica, sin pasar por la CPU.
De esta forma, se libera a la CPU de la tarea de la compresión y descompresión de datos y la GPU puede acceder directamente a lo que necesite.
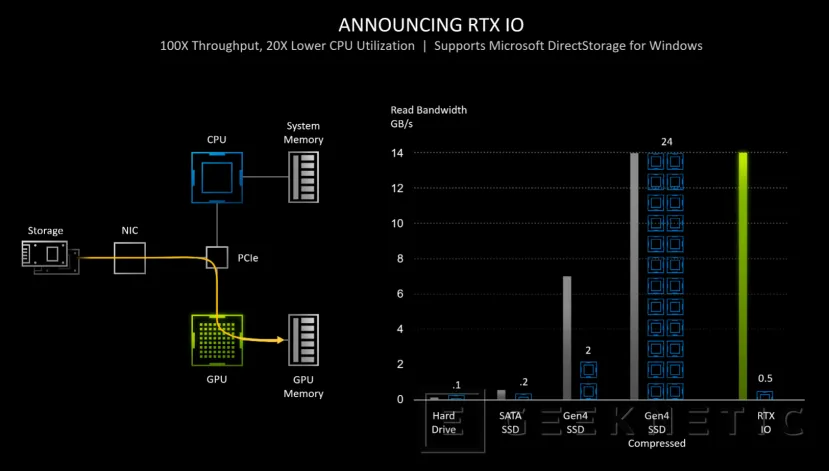
En la Demo que ha mostrado NVIDIA, los tiempos de carga se reducen de manera considerable, tardando 5 segundos desde un SSD NVMe Gen4 a 1,5 segundos.
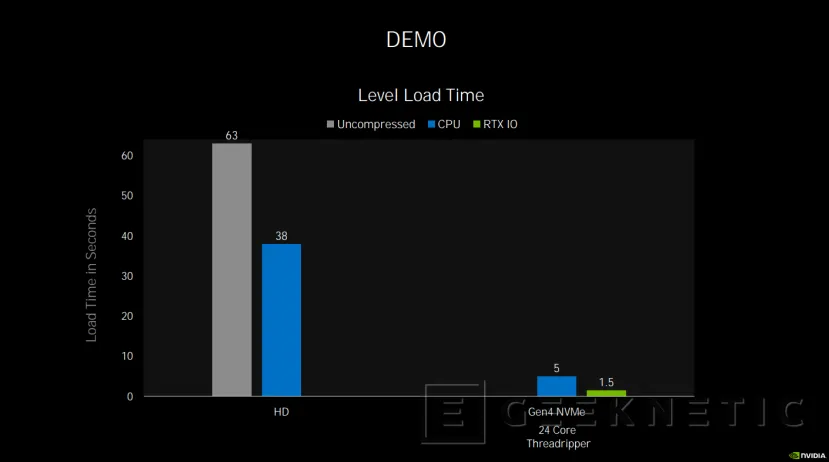
Por el momento no sabemos como afectará esto a los juegos y NVIDIA tampoco ha confirmado qué juegos lo llevarán. Sí que sabemos que dependerá del desarrollador del juego el implementarlo o no. Nos gustaría pensar que Cyberpunk 2077, que es un juego que ya se ha confirmado que soportará RTX y DLSS 2.0, también integrará esta tecnología. Al fin y al cabo qué mejor juego para aprovechar las velocidades de almacenamiento que uno como este que ya se ha confirmado que ocupará más de 200GB.
Reduciendo la latencia con NVIDIA Reflex
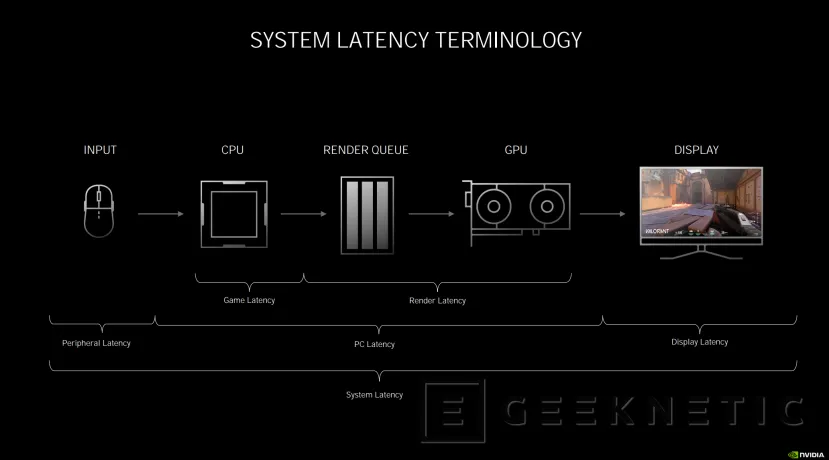
En juegos, la latencia hace referencia al retardo que hay entre que el usuario realiza una acción con el ratón o teclado, por ejemplo, hasta que lo vemos en la pantalla. En medio está la CPU, la cola de renderizado, la propia GPU y, naturalmente, la propia rapidez del teclado o de la pantalla.
Dependiendo del punto en el que consideremos ese retardo, hablaremos de latencia de periférico, latencia del PC, que incluye la latencia del juego y de renderizado, o la latencia de la pantalla.
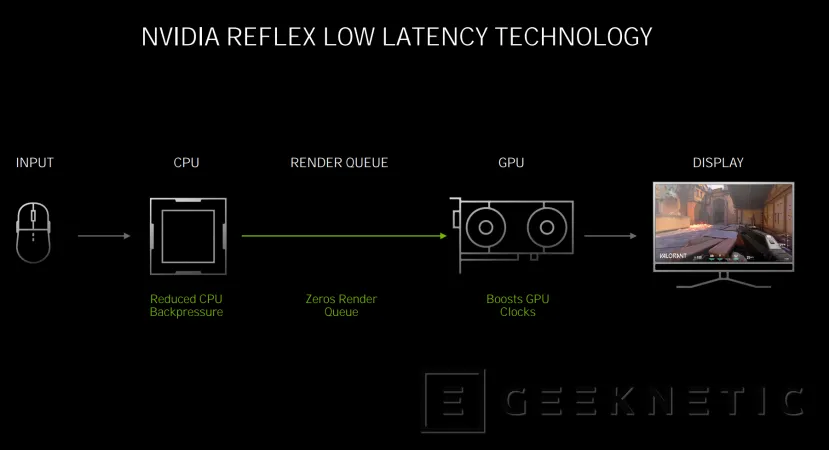
NVIDIA Reflex actúa sobre la latencia que afecta desde la CPU hasta la GPU, reduciendo la que puede producirse en el propio juego y la CPU, bajando la cola de renderizado hasta cero, y aumentando la velocidad de funcionamiento de la GPU para conseguir unos tiempos de respuesta mejorados.
Esto se puede aplicar con detalles de calidad altos, sin ser necesario reducir los niveles de detalle para reducir la cola de renderizado o la espera en CPU.
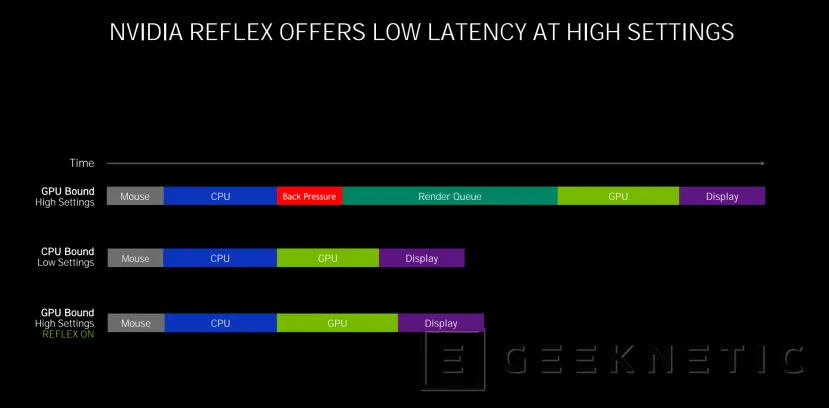
La tecnología NVIDIA Reflex ha sido creada teniendo en mente a los jugadores de eSports, sean profesionales o no, un mundo donde se intenta ajustar el rendimiento al máximo para conseguir el mejor desempeño. De hecho, estudios realizados por la propia NVIDIA muestran que una reducción de la latencia de 100 a 20 ms puede aumentar hasta en un 37% la mejora en apuntado en un juego de tipo Shooter. Y bajar de 20ms a 12 ms reduce el tiempo en abatir a un enemigo de 1,53s a 1,35 s.
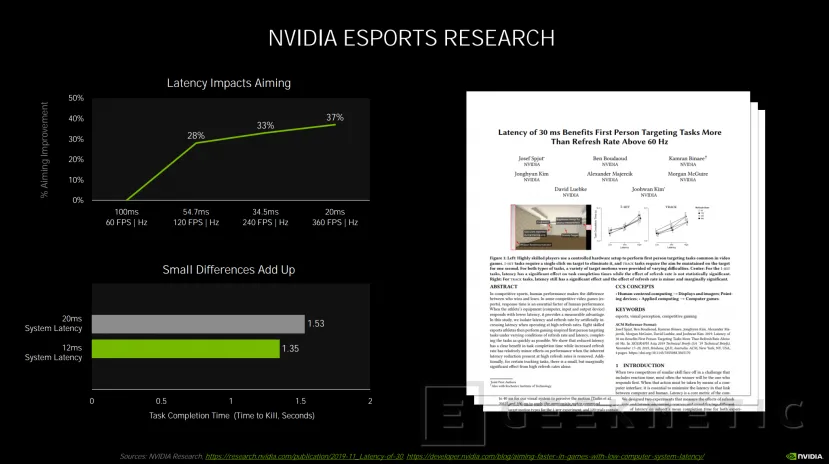
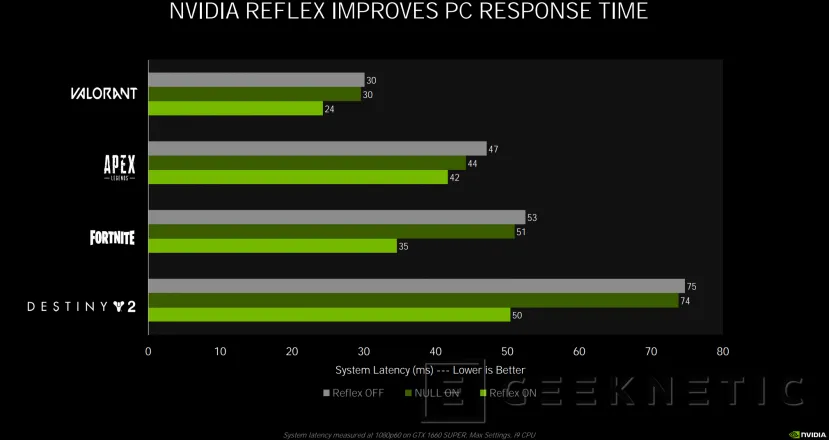
En juegos como Destiny 2, esta tecnología reduce de 75 ms a 50 ms los tiempos de respuesta, en valorant de 30 a 2. Por el momento, NVIDIA Reflex será compatible con juegos como APEX Legends, COD Black OPs Cold War, COD Warzone, COD MW, Fortnite, KOvaak 2.0 y Valorant.
Además, se puede mejorar la respuesta acompañando a esta tecnología de uno de los nuevos monitores de 360 HZ con G-SYNC.
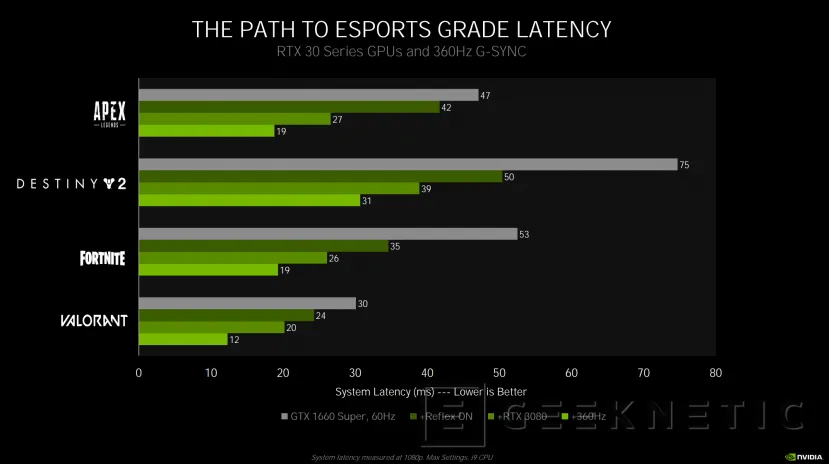
Esta nueva generación cuenta con una placa dedicada con G-SYNC y un analizador de latencia Reflex integrado que permite medir de manera directa la latencia de todo el sistema, incluso con un puerto USB para monitorizar el ratón junto al resto del equipo.
Los datos recogidos se pueden superponer mediante la herramienta GeForce Experience.

Desde la serie GeForce GTX 900 en adelante se podrá hacer uso de esta tecnología en los juegos que podemos ver en la parte izquierda de la imagen de arriba.
Conclusión
La primera generación de gráficas RTX 20 y la arquitectura Turing sentaron las bases para la llegada del raytracing al usuario doméstico junto a funciones aceleradas por IA impensables hasta ahora como el DLSS gracias a una arquitectura que, más allá de los shaders, integraba elementos dedicados como los RT Cores y Tensor Cores.
Ahora, con Ampere y las RTX 30, se consolidan estas tecnologías con una nueva generación, acompañadas de un rendimiento sin precedente en el mundo del PC y haciendo que, por fin, el juego a 4K sin restricciones y el raytracing junto a DLSS 2.0 sea una realidad, lo que, sin duda, traerá nuevos títulos Triple A al mercado con soporte para estas tecnologías como el esperado Cyberpunk 2077.
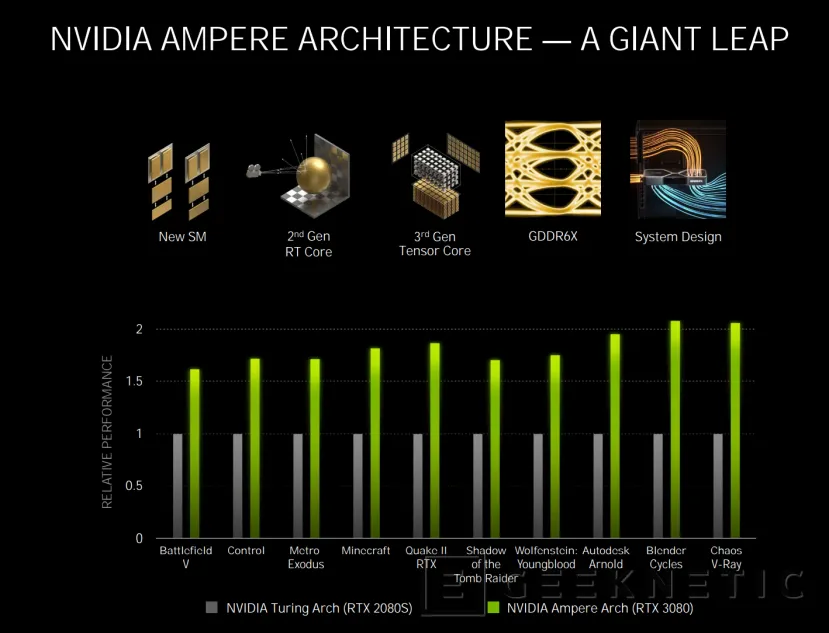
Todas las mejoras introducidas en Ampere que hemos visto permiten ese rendimiento extra que prácticamente duplica al de la generación anterior, con un 1,9x más de potencia gráfica y unos precios similares o incluso más económicos que las RX 20. Sin duda, una buena época para los amantes del gaming en PC.
Fin del Artículo. ¡Cuéntanos algo en los Comentarios!








