


AMD Radeon RX 9070 Series: Así consigue la Arquitectura RDNA 4 Multiplicar el Rendimiento en Raytracing e IA
por Antonio DelgadoIntroducción y especificaciones técnicas de las AMD Radeon RX 9070 y RX 9070 XT
Las AMD Radeon RX 9070 y RX 9070 XT hicieron un pequeño acto de aparición en el CES 2025, en enero de este año. Es hoy cuando AMD ha decidido presentarlas más en detalle de cara a un lanzamiento muy esperado para los entusiastas del mundo del PC.

Estas dos tarjetas estrenan la nueva arquitectura AMD RDNA 4 con distintas mejoras enfocadas a un mayor rendimiento, eficiencia, y tecnologías para mejorar el desempeño en raytracing, multimedia e Inteligencia artificial.
A lo largo de este artículo desgranaremos al detalle todos los entresijos de la arquitectura RDNA 4 que llevan sus GPU NAVI 4, las nuevas tecnologías que llegarán con estas tarjetas, como FSR 4, además de los datos de rendimiento que ha mostrado AMD para estas Radeon RX 9070 XT y RX 9070.

Antes de comenzar, un pequeño repaso sobre las especificaciones técnicas de las AMD Radeon RX 9070 XT y las RX 9070. Ambas estarán basadas en la GPU Navi 4 con arquitectura RDNA 4 y contarán con 16 GB de memoria RAM. La principal diferencia entre ellas la encontramos en las velocidades y número de unidades de cómputo.
En el caso del modelo más potente, la RX 9070 XT, tenemos 64 CUs RDNA 4, con sus 64 aceleradores de Raytracing y sus 128 aceleradores de IA con los que consigue hasta 1.557 TOPS en INT4. Su velocidad máxima boost de serie será de 2,97 GHz. Su TBP será de 304 W.
La AMD Radeon RX 9070 llegará con 8 CUs menos, quedándose con 56 aceleradores RT, 112 aceleradores de IA con 1.165 TOPS en INT4, y una velocidad máxima de 2,52 GHz. Todo ello con un TBP (energía de toda la tarjeta) de 220 W.

Características Técnicas de las AMD Radeon RX 9070 XT y Radeon RX 9070
| Especificaciones | RADEON RX 9070 XT | RADEON RX 9070 |
|---|---|---|
| GPU | Navi 4 (53,9 millones transistores) | Navi 4 (53,9 millones transistores) |
| Arquitectura | RDNA 4 | RDNA 4 |
| Proceso de Fabricación | 4nm | 4nm |
| Unidades de Cómputo | 64 | 56 |
| Aceleradores de Rayos | 64 | 56 |
| Aceleradores de IA | 128 | 112 |
| SPs | 4096 | 3584 |
| Frecuencia Boost GPU | 2,97 GHz | 2,52 GHz |
| Pico de Rendimiento en INT4 AI TOPS | 1.557 TOPS con Sparsity | 1.156 TOPS con Sparsity |
| Memoria | 16 GB GDDR6 256 bit | 16 GB GDDR6 256 bit |
| Velocidad Memoria | 20 Gbps | 20 Gbps |
| Caché | 64 MB Infinity caché 3ª gen | 64 MB Infinity caché 3ª gen |
| Conectividad PCIe | PCIe 5.0 x16 | PCIe 5.0 x16 |
| TBP | 304 W | 220 W |
| Conectores de Pantalla | HDMI 2.1b
DisplayPort 2.1a |
HDMI 2.1b
DisplayPort 2.1a |
La Arquitectura RDNA 4 al detalle: Todas las Mejoras en Raytracing, IA y mucho más
La arquitectura RDNA se estrenó en las AMD Radeon RX 5000 Series en el año 2019, le siguió RDNA 2 dando vida a las Radeon RX 6000 en 2020 y finalmente, RDNA 3 llegó con las RX 7000 a finales de 2022. Posteriormente, RDNA 3.5 surgió como una actualización para APUs y GPUs de portátiles.
Ahora toma el testigo la cuarta generación RDNA 4, para dar vida a las AMD Radeon RX 9000 Series, con las Radeon RX 9070 XT y RX 9070 como lanzamientos iniciales. Estas gráficas no competirán con la gama más alta (y prohibitiva) de NVIDIA, pero buscan hacerse un hueco en la gama media/media-alta batiéndose en modelos como las RTX 5070 y RTX 5070 Ti.

RDNA 4 es una arquitectura que introduce distintas mejoras en el ámbito del rendimiento en juegos, con mejoras en el soporte para raytracing, sin olvidarse de la Inteligencia Artificial para tareas de creación de contenido y también para tecnologías como FSR 4, path tracing o la generación de fotogramas. También tenemos mejores capacidades de codificación de vídeo y streaming. Todo ello con 16 GB de memoria GDDR6.
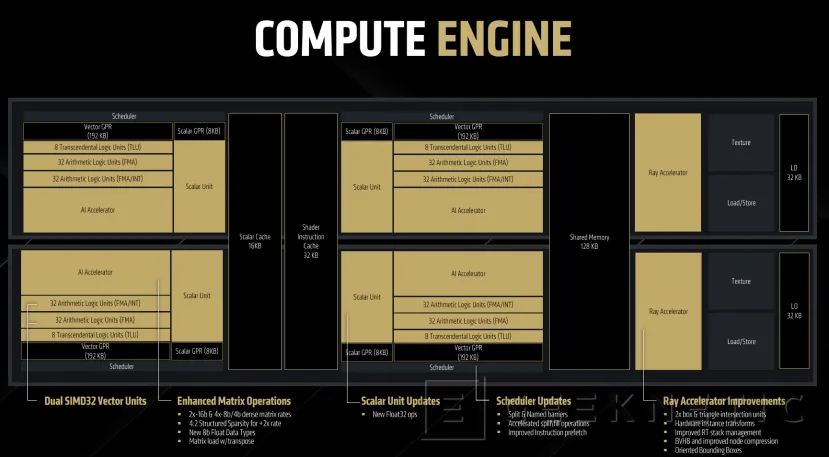
Diseño y elementos de las Unidades de Cómputo de RDNA 4
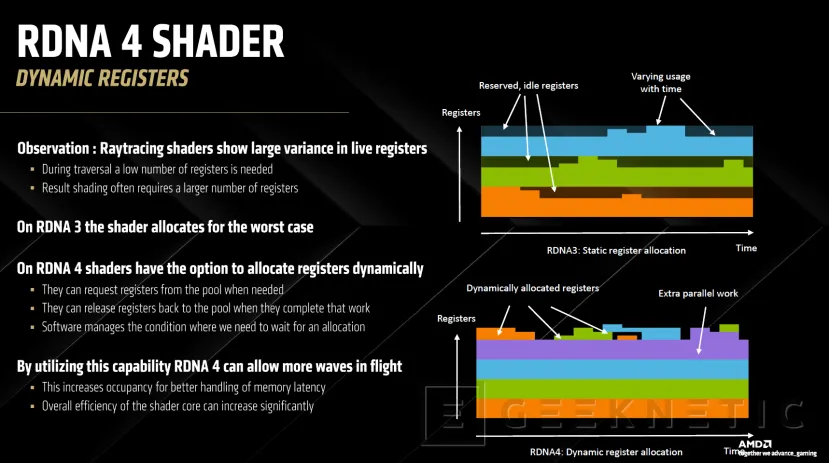
RDNA 4 ha rediseñado las unidades de cómputo o CUs donde se integran los distintos aceleradores. Se han mejorado las unidades escalares, la reserva de registros dinámicos y el subsistema de memoria para conseguir una mayor eficiencia y velocidades de reloj más elevadas.

RDNA 4 combina cada CU en pares de dos, de tal manera que cada dos CUs cuentan con acceso a memoria y cachés compartidas. De esta forma, cada par de CUs comparten 128 KB de memoria, una caché escalar de 16KB y una caché de instrucciones para sombreadores (shaders) de 32 KB. Cada CU cuenta también con sus propios 32 KB de caché L0.
Dentro de cada CU tenemos una unidad de acelerador de Raytracing, dos aceleradores de IA y dos unidades escalares, además, dividido en dos grupos, se incluyen un total de 16 unidades lógicas transcendentales (TLU), 128 unidades aritmético-lógicas de las cuales 64 son FMA y otras 64 FMA/INT.
Mejoras en los Aceleradores de Raytracing de Tercera Generación
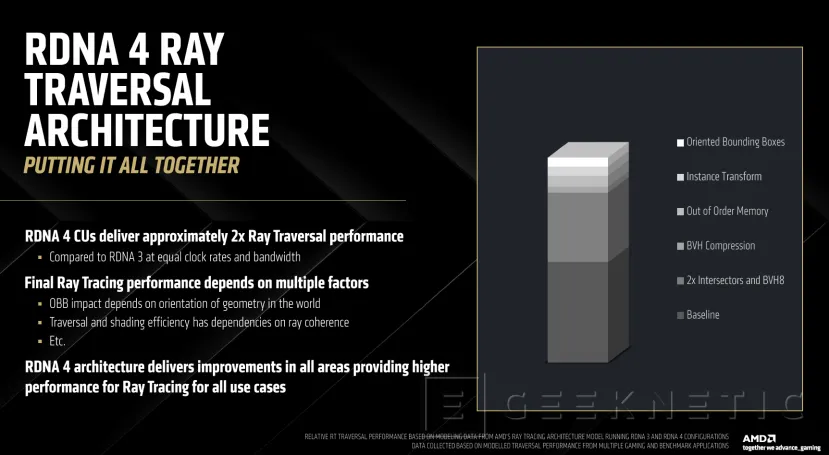
Las unidades de aceleradores de raytracing de tercera generación que incluye RDNA 4 han recibido también importantes mejoras. Se ha multiplicado por dos las unidades de intersección de triángulos y cajas, además de mejorar la gestión de pilas, compresión de nodos y otras tecnologías.
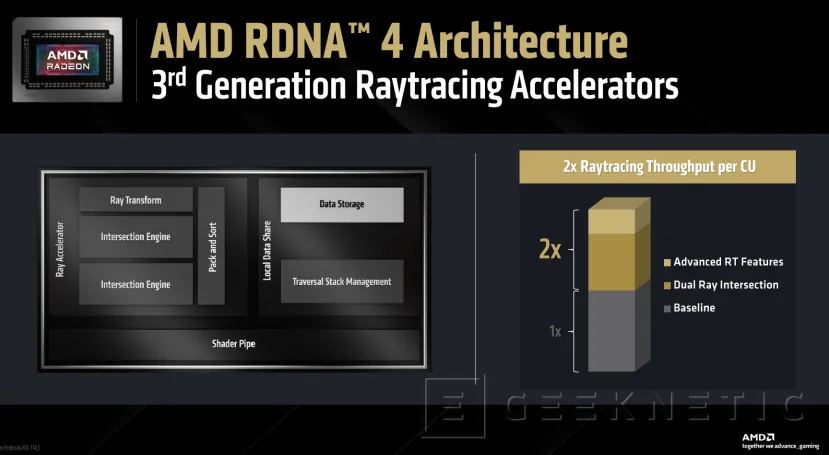
En total, se duplican las unidades a 8 Rayos/Box y 2 Rayos/Triángulos, el doble que en RDNA 3, incorporando también hardware dedicado para transformación de instancias y mejoras en la gestión de la pila.
También se utiliza BVH8 para reducir la latencia y en número de pasos necesarios. BVH es una estructura de datos (Bounding Volume Hierarchy) que se utiliza en raytracing para acelerar la detección de colisiones e intersecciones. En RDNA 4, la mejora de BVH8 (en comparación con BVH4 de RDNA 3) significa que ahora cada nodo puede contener hasta 8 hijos en lugar de 4, reduciendo la cantidad de pasos necesarios para recorrer la jerarquía y, por lo tanto, mejora la eficiencia del trazado de rayos.
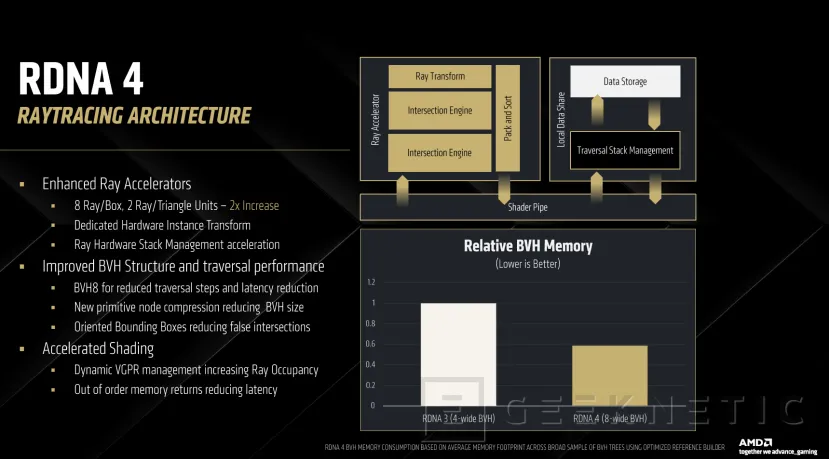
También se ha mejorado la gestión de la aceleración de sombreados, con gestión dinámica de VGPR (Vectores de propósito general) para mejorar la ocupación de rayos y ejecutar más operaciones en paralelo con menor latencia.
Las mejoras en la gestión de memoria "fuera de orden" permiten optimizar el rendimiento en cargas de trabajo de trazado de rayos al no seguir un orden lineal en el acceso a los datos.
Con esto, se reduce la latencia en solicitudes de datos a memoria, un punto crítico al ser las cargas de trabajo de raytracing muy sensibles a la latencia. También se ha optimizado el acceso a estructuras, BVH, texturas y buffers para sombreados y otros procesos.
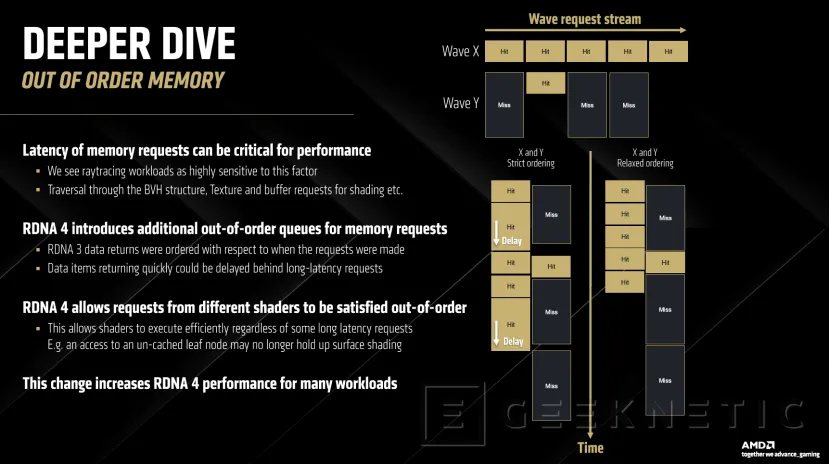
Las colas de acceso a memoria "fuera de orden" son una mejora que permite que el acceso a los datos no se retrasen ante peticiones más lentas. En RDNA 3, las solicitudes se procesaban en orden, haciendo que se pudieran dar estos retrasos a la espera de datos de peticiones más lentas.
Con RDNA 4 se pueden solicitar datos desde distintos shaders sin seguir ese orden preestablecido, evitando estos retrasos.
Otra mejora de RDNA 4 de cara al procesamiento raytracing son los que se conoce como OBB. Los Oriented Bounding Boxes (OBB), que vendría a ser una traducción de "Cuadros Delimitadores Orientados", permiten optimizar el recorrido de ratos para detección de colisiones.
Se diferencian de las AABB tradicionales (cuadros delimitadores alineados en ejes), en que las AABB se alinean en los ejes XYZ haciendo que se puedan generar áreas vacías cuando la geometría no está alineada en esos 3 ejes, mientras que las OBB permiten la rotación y ajuste según la orientación de la propia geometría a mostrar, así se mejora la eficiencia al reducir los espacios vacíos.
Con OBB se pueden conseguir mejoras del rendimiento de hasta el 105 dependiendo de la geometría a representar. En la siguiente imagen se puede ver un esquema como al utilizar OBB se evitan muchos espacios vacíos que no son realmente necesarios.

A nivel de sombreado, los registros dinámicos permiten que se vayan reservando según se necesiten. En el caso de RDNA 3, los registros se reservaban teniendo en cuenta el peor caso posible, desperdiciando recursos y aunmentando la latencia innecesariamente.
La combinación de todas estas mejoras en RDNA 4 permiten ampliar el rendimiento en procesado de trazado de rayos en todas las áreas y casos de uso e implementación.
El futuro es el PathTracing
El Raytracing se ha convertido en una tecnología muy utilizada en los últimos lanzamientos de juegos AAA, tanto en PC como en consolas, para añadir efectos más realistas de iluminación, reflejos y sombras.
La evolución del uso del raytracing para este tipo de efectos va hacia lo que se conoce como "Path Tracing", una tecnología que empieza a implementarse ahora en algunos títulos y que va camino de convertirse en el futuro de los juegos y motores gráficos más capaces a nivel gráficos.

Mientras que el raytracing utiliza los "rayos de luz" de distintas maneras para generar reflejos, sombras y otros elementos de iluminación, basándose en una simulación de como interactúan con los objetos en el mundo real pixel a pixel; el PathTracing utiliza el hardware dedicado al raytracing de otra manera distinta.
PathTracing es una técnica más avanzada que simula como la luz viaja en distintas direcciones y rebota en distintas superficies y objetos para crear múltyiples ratos por cada píxel y tener una simulación realista de la iluminación global de una escena.
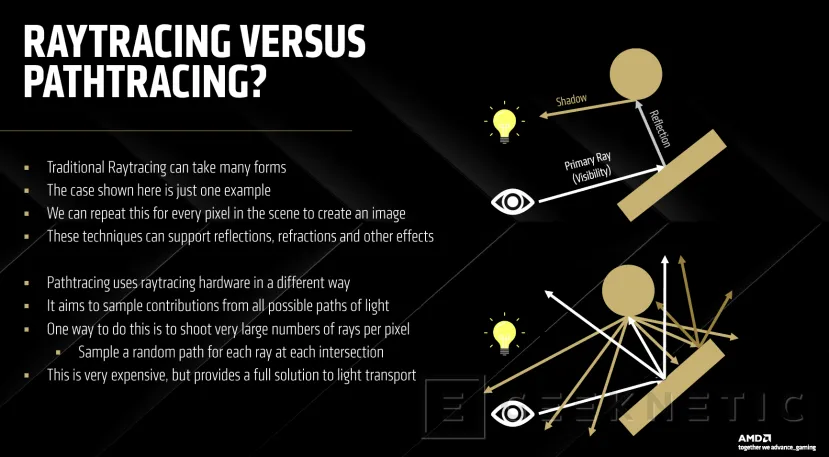
El resultado es una escena mucho más precisa y realista, pero con un costo computacional mucho más elevado. De ahí que surja la necesidad de aplicar otros métodos para conseguir hacerlo viable. Ahí entra en juego el uso de sistemas de IA para hacer supersampling y reconstrucción de rayos.

NVIDIA lo introdujo en su tecnología DLSS 3.5 y AMD RDNA 4 añade soporte para tecnologías de supersampling neuronal y reducción de ruido.

Más rendimiento en streaming y multimedia
Las tarjetas gráficas también son las encargadas de gestionar la decodificación y codificación de vídeo, y hoy más que nunca, el auge del streaming las convierte en dispositivos clave.
RDNA 4 ha mejorado las partes dedicadas a esta tarea, con un 25% de ganancia de rendimiento en codificación de baja latencia con el codec H.264. También hay una mejora del 11% en la codificación de vídeos HEVC (H.265).
Se ha mejorado la eficiencia en la codificación de vídeo AV1 con fotogramas B, y también se ha conseguido un 30% más de rendimiento en codificación a 720p, una resolución bastante utilizada a la hora de hacer streaming.
RDNA 4 está optimizada para FFMPEG, Handbrake y OBS. Además, se ha mejorado el rendimiento en la reproducción de vídeo de bajo consumo, con más de un 50% de rendimiento en vídeos AV1 y VP9.

En la parte de monitores, RDNA 4 incluye mejoras en la optimización de energía para FreeSync. También se añade soporte por hardware para la tecnología Flip Queue o inversión de cola, que permite ahorrar uso de CPU en reproducción de vídeo al delegar la programación de los fotogramas en la GPU.
También se ha mejorado la tecnología de nitidez de imagen Radeon Image Sharpening 2, consiguiendo más calidad y soporte para todas las APIs gráficas.

Aceleradores de IA de segunda generación en RDNA 4
Hoy en día, la Inteligencia Artificial se ha colado en todos los ámbitos, algunos en forma de márquetin, y en otros con aplicaciones realmente prácticas. De lo que no hay duda es que la GPU se han convertido en un elemento aún más importante que antes, abarcando más usos que el acelerar gráficos, para añadir elementos hardware capaces de acelerar el procesamiento de funciones de IA cada vez más exigentes.
La arquitectura RDNA 4, como ya hemos visto, incluye un acelerador de IA de segunda generación en cada Unidad de Cómputo o CU.
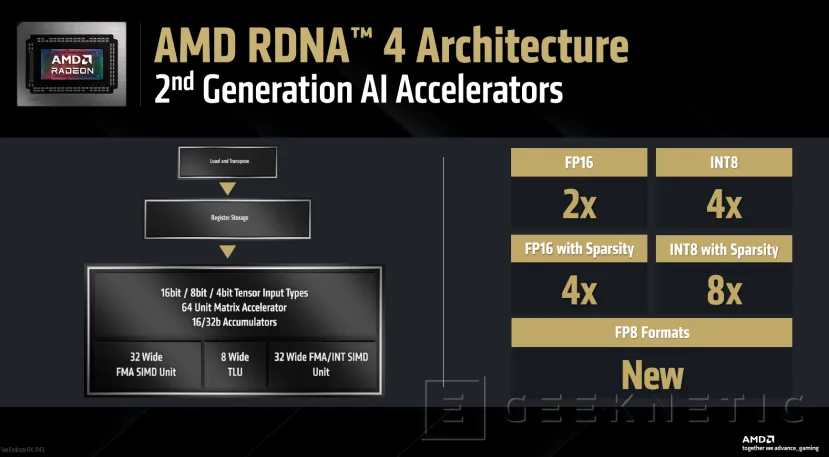
Esta nueva generación multiplica por dos la capacidad de procesado FP16, por cuatro el procesador INT8 y FP12 con Sparsity (eliminación de valores 0 o insignificantes para optimizar la eficiencia en el cálculo de modelos de IA); y multiplica por 8 el rendiimiento en INT88 (también con Sparsity).
Además, se añade soporte para formatos FP8 por primera vez en los aceleradores IA de RDNA.
Los aceleradores de IA de RDNA 4 se centran en sistemas de creación de contenido con IA y también en aplicaciones para juegos, todo ello basándose en las experiencias previas con GPUs Radeon e Instinct.
Se han introducido mejoras en operaciones WMMA (Wave Matrix Multiply Accumulate) para aumentar la eficiencia y reducir el consumo en operaciones con matrices.
Las operaciones matemáticas se procesan 4 veces más por CU que en RDNA 3, soportando tensor cores de 4, 8 y 16 bits, con aceleradores de matrices de 64 bits y acumuladores de 16 y 32 bits.

En cuanto al Sparsity del que os hemos hablado antes, es una técnica utilizada en procesamiento IA en varios ámbitos y que busca descartar datos con poca relevancia o importancia para mejorar el rendimiento y eficiencia, centrándose en los datos importantes.
En RDNA 4 se añade soporte para Sparsity Estructurado 4:2 (que sifgnifica que de 4 valores de una matriz, se procesan 2 activamente) con el que prometen hasta el doble de rendimientio con más eficiencia energética.
Con estas mejoras, RDNA 4 promete hasta el doble de rendimiento IA por CU.
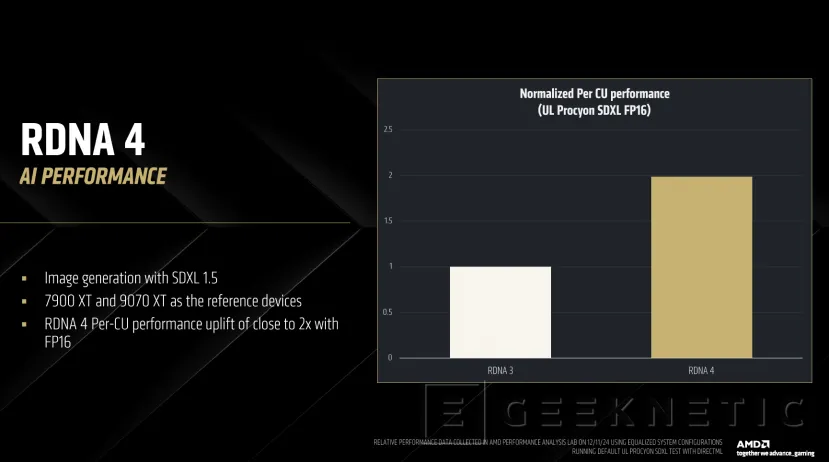
Os dejamos con un par de esquemas que muestra todas las novedades y mejoras de RDNA 4 a modo de resumen.
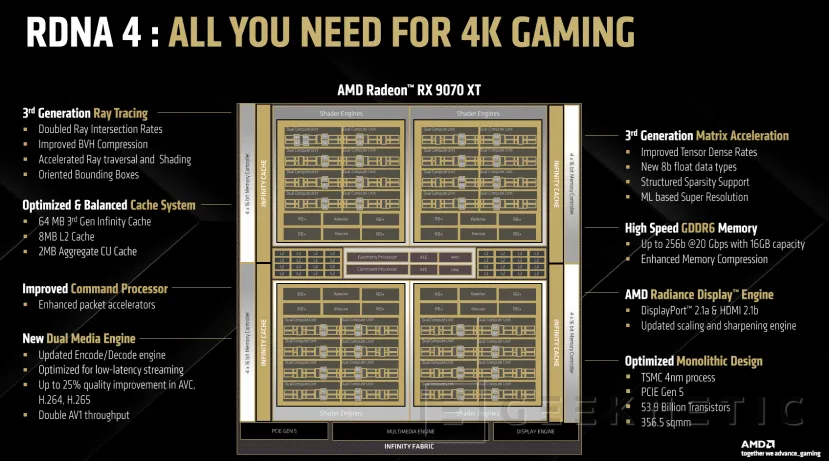
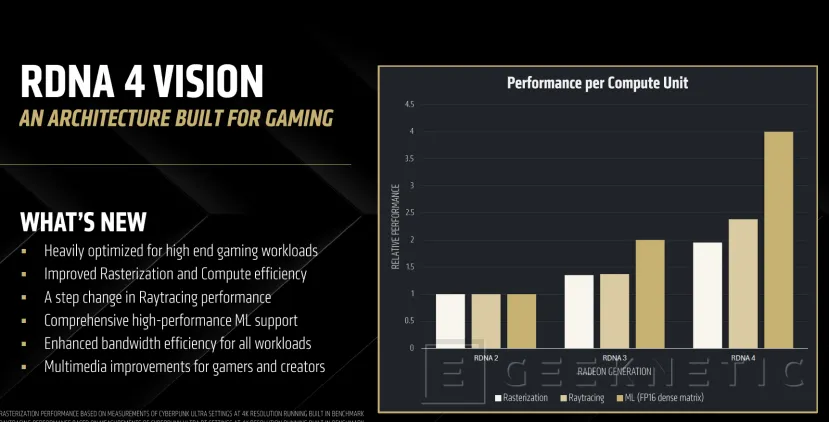
Rendimiento de las AMD Radeon RX 9070 XT y RX 9070
AMD ha desvelado algunos datos de rendimiento de RDNA 4 con las AMD Radeon RX 9070 XT y RX 9070. Según la propia compañía, estas gráficas se colocarán a medio camino entre las RX 7900 GRE y las Radeon RX 7900 XT y RX 7900 XTX. Son unas gráficas centradas en juegos 1440p y 4K que buscan ofrecer la mejor relación entre prestaciones y precio.
Por tanto, tal y como ya sabíamos, no serán gráficas para la gama más alta, sino que buscarán colocarse como una opción equilibrada en rendimiento y precio.

En 4K, AMD promete que la AMD Radeon RX 9070 XT conseguirá un rendimiento un 42% superior al de la 7900 GRE en juegos 4K con detalle Ultra. En el caso de la AMD Radeon RX 9070, tendremos un rendimiento medio un 21% superior al de la Radeon RX 7900 GRE en juegos 4K con detalle ultra.

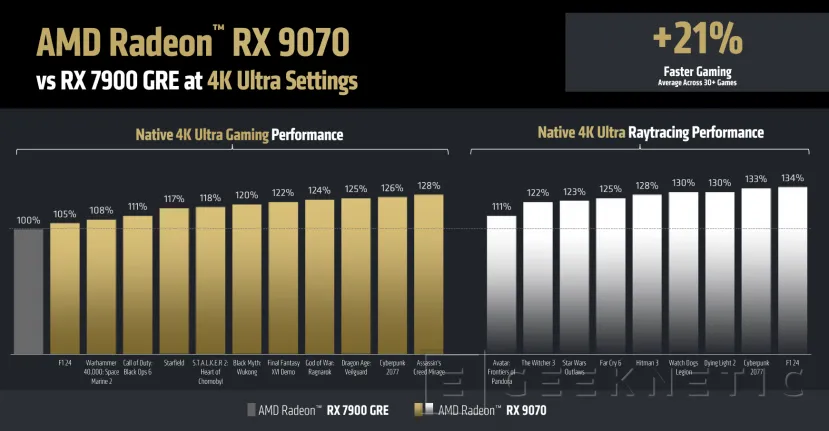
Será en esos juegos 4K donde se note más diferencia. En el caso de los juegos a 1440p, con detalle Ultra también, el rendimiento de la RX 9070 XT será un 38% más potente que la 7900 GRE, con un 20% más de rendimiento en el caso de la RX 9070.


Hablamos de potencia bruta, ya que la tecnología FSR 4 con interpolado de fotogramas promete multiplicar el rendimiento de las AMD Radeon RX 9070 Series en hasta 3,7 veces.
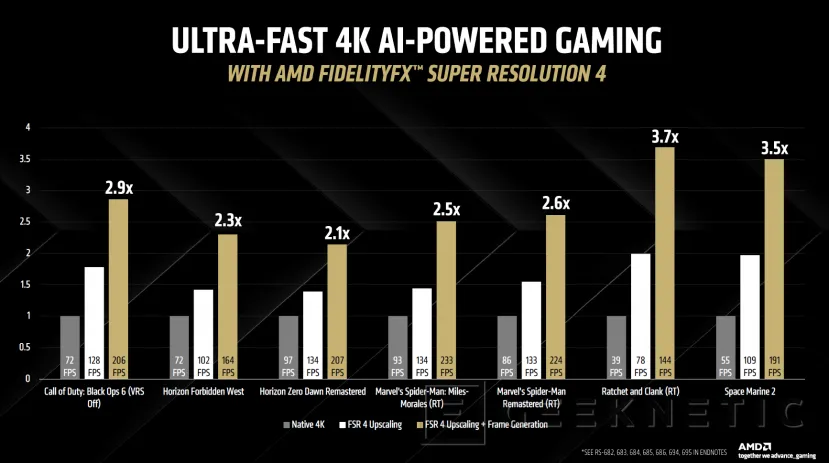

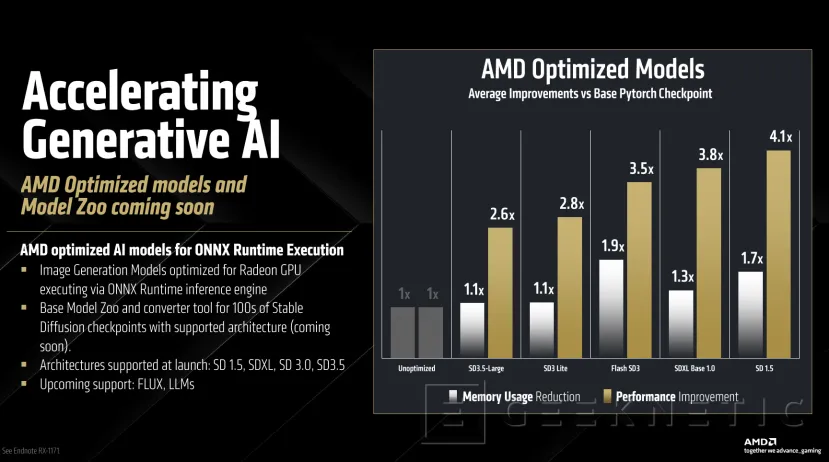
Habrá también mejoras en rendimiento con sistemas generativos de inteligencia artificial con el entorno de ejecución ONNX para inferencia. AMD promete mejoras de rendimiento de hasta 4,1x, con una reducción de memoria que se queda a las puertas de conseguir utilizar la mitad de memoria en algunos casos.
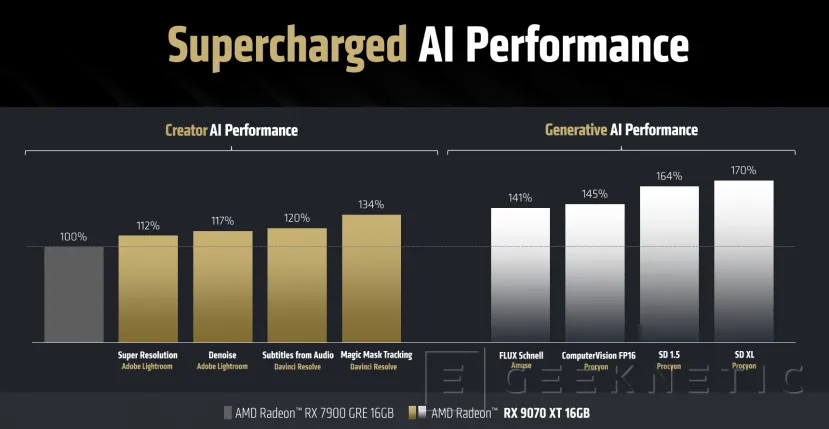
Las mejoras de rendimiento en IA en programas de creación y edición de contenido llegan al 134% en funciones como Magic Mask de Davinci Resolve, una tecnología que hemos utilizado varias veces para probar el rendimiento de NPUs. En el caso de plataformas de AI generativa, tenemos hasta 170% de rendimiento respect ode la RX 7900 GRE.
FSR 4 ofrecerá más del triple de rendimiento
La tecnología AMD FSR 4 será una de las novedades más importantes de esta nueva generación de tarjetas gráficas. AMD Adoptará la tecnología de Machine Learning y renderizado neuronal en la cuarta generación de FSR, creada específicamente para RDNA 4 basándose en la API de FSR 3.1.
Combinará tecnologías como el reescalado, la generación de fotogramas y la tecnología AMD Anti-Lag para conseguir multiplicar el rendimiento por tres.

Gracias a las capacidades de aceleración de IA de RDNA, FSR 4 utilizará un modelo de IA entrenado por AMD en sistemas con GPUS AMD Instinct para conseguir imágenes de mayor calidad y con un mejor rendimiento.

La tecnología de reescalado se combinará con la generación de fotogramas y anti-Lag para reducir la latencia y aumentar los FPS aprovechando los 779 TOPS de aceleración IA de las Radeon RX 9070 XT con RDNA 4.

AMD presume de haber utilizado toda su tecnología para el desarrollo de FSR 4. Naturalmente, se han utilizado CPUs con arquitectura ZEN y aceleradoras XDNA para el desarrollo de FSR 4, posteriormente se han entrenado los modelos en sistemas dotados de procesadores EPYC y aceleradoras AMD Instinct, todo ello para diseñar una tecnología para las GPUs gaming con RDNA 4 y combinarlas con el software de la compañía.

AMD promete mejoras de rendimiento de más del triple de FPS con FSR en modo rendimiento en juegos como Space Marine II.
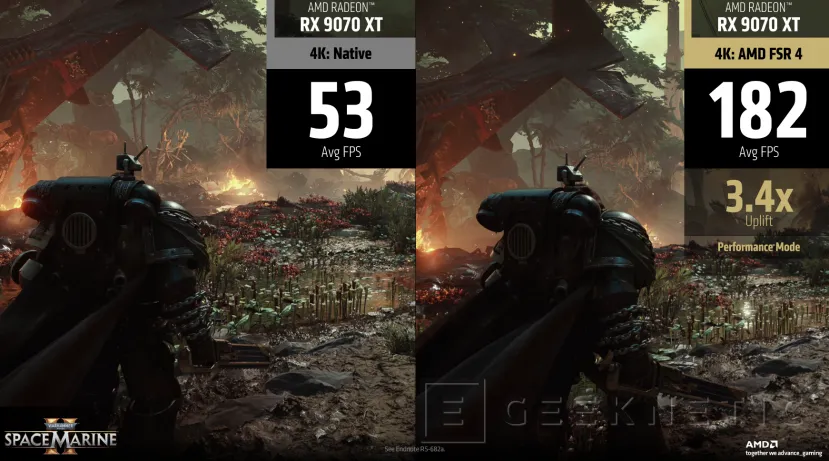
Incluso en modo rendimiento, AMD promete que FSR 4 conseguirá un nivel de detalle similar al de una escena renderizada en 4K nativo. Recordemos que FSR y otras tecnologías de reescalado, se basan en renderizar una imagen a menor resolución para generar un fotograma de mayor resolución a menor coste computacional.


Algo muy interesante es que FSR 4 tendrá soporte para más de 30 juegos en el momento del lanzamiento, incluyendo títulos como Call of Dury Black Ops 6.
A lo largo del año 2025, AMD promete que habrá más de 75 juegos con soporte nativo para FSR 4.

HYPER-RX con AMD Fluid Motion Frames 2.1: Más rendimiento en miles de juegos a nivel de driver
Además de las mejoras que trae FSR 4 y que acabamos de repasar, AMD también ha potenciado su tecnología HYPR-RX y no solo para RDNA 4.
HYPR-RX es un conjunto de tecnologías de AMD que se gestiona con perfiles optimizados para juegos, de tal manera que tecnologías como Anti-Lag, Radeon Boost, Radeon Super Resolution (RSR) y AMD Fluid Motion Frames 2.1, puedan funcionar en juegos.
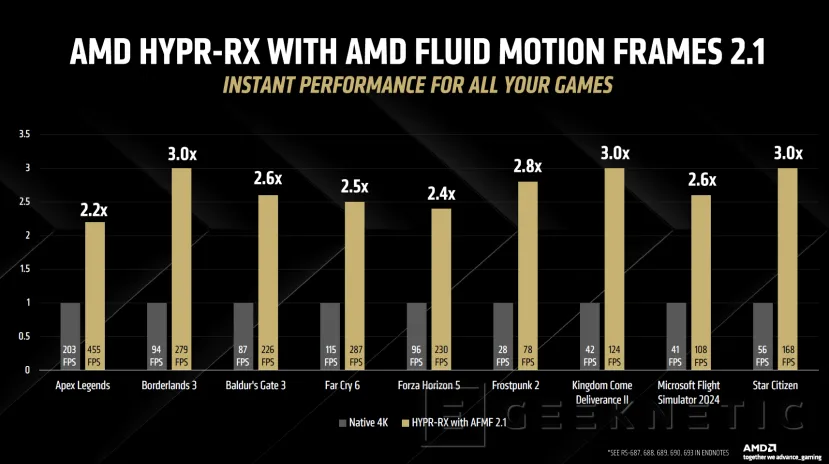
A modo de comparativa, si FSR 4 tiene soporte en algo más de 30 juegos al momento de lanzamiento y FSR 2/3 tiene soporte para más de 400 juegos. En 2025 habrá soporte para más de 1.000 juegos con HYPR-RX

Esta tecnología funciona a nivel de drivers, por lo que no es necesario que los desarrolladores añadan soporte. Por ejemplo, en juegos como Star Citizen se puede multiplicar por 2,9 veces el rendimiento al activar HYPR-RX con reescalado y generación de fotogramas.

La nueva generación de AMD Fluid Motion Frames 2.1 permite generar fotogramas intermedios en juegos que no tienen soporte dedicado. Es una tecnología que funciona a nivel de drivers y que será compatible con las AMD Radeon 9070 Series, pero también con las Radeon RX 6000, RX 700 y también con CPUs AMD Ryzen AI 300 con gráficos integrados.
Las mejoras de Fluid Moiton Frames 2.1 incluyen una reducción en el ghosting, recuperación de detalles de pequeño tamaño, y mejoras en la nitidez cuando se superponen textos e interfaces de usuario en juegos.

Es una manera de poder multiplicar el rendimiento en juegos que no han implementado FSR y generación de fotogramas dedicada, soportando un mayor número de juegos para los usuarios de tarjetas gráficas Radeon.
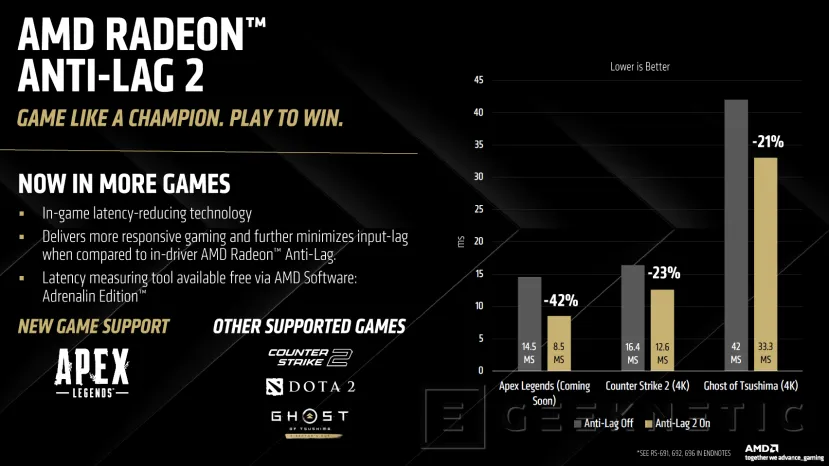
Anti-Lag 2 está presente ahora en más juegos para reducir la latencia, es una tecnología que debe soportarse en juegos y que , al contrario que la primera generación de Anti-Lag que se implementaba a nivel de driver, consigue minimizar más el input lag y mejorar la respuesta en juegos.
AMD promete que, además de AMD Fluid Motion Frames 2.1, HYPR-RX recibirá más funciones pronto.

Fin del Artículo. ¡Cuéntanos algo en los Comentarios!








